Dnes ráno proběhl pravidelný seminář - Ranní káva s Oracle technologiemi, tentokrát na téma Oracle (Hyperion) ESSBASE.
Prezentaci ze semináře si můžete stáhnout zde.
středa 24. září 2008
čtvrtek 18. září 2008
Jak na stavové / neaditivní ukazatele
Stavové / neaditivní ukazatele patří mezi další typické ukazatele v BI. Jejich využití je nejčastěji v repotech zobrazujících prvotní nebo poslední stav v čase (tj. přes časovou dimenzi), jako je např. stav (počet) zboží na skladě, kdy stav za kvartál 2001-Q1 je roven stavu posledního měsíce v tomto kvartálu tj. 2001-Březen a stav za rok 2001 je rovem stavu posledního kvartálu v daném roce tj. 2001-Q4.
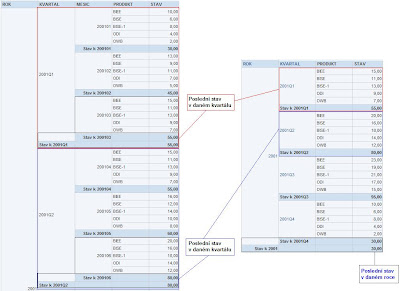
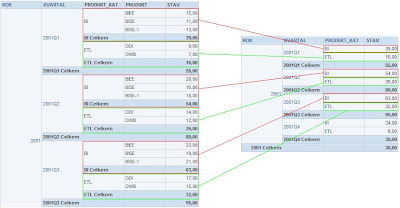
Oproti tomu, když se stejný ukazatel analyzuje přes jiné dimenze, tak by měl data agregovat dle použité funkce, jako je např. SUM().
Jak na to
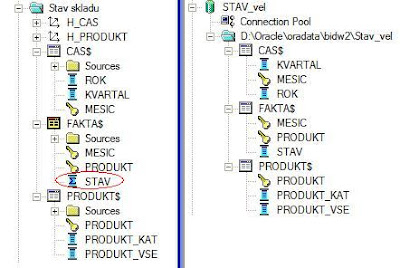
1/ V BI Metadata repository založte Fyzickou vrstvu a nad ní vytvořte Business model včetně hierarchií pro dimenze.
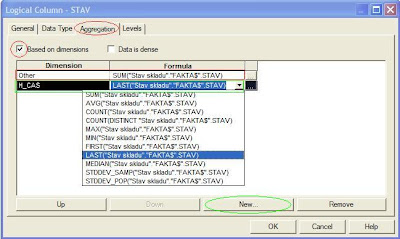
2/ Pro vybraný ukazatel v záložce „Aggregation“ zaškrtněte „Based on dimensions“. Kde nejprve pro ostatní (Other) dimenze zvolte požadovanou agregační funkci, poté přidejte časovou dimenzi (tlačítko New...) a u ní vyberte funkci LAST() nebo FIRST().
Erik Eckhardt.

Oproti tomu, když se stejný ukazatel analyzuje přes jiné dimenze, tak by měl data agregovat dle použité funkce, jako je např. SUM().

Jak na to
1/ V BI Metadata repository založte Fyzickou vrstvu a nad ní vytvořte Business model včetně hierarchií pro dimenze.

2/ Pro vybraný ukazatel v záložce „Aggregation“ zaškrtněte „Based on dimensions“. Kde nejprve pro ostatní (Other) dimenze zvolte požadovanou agregační funkci, poté přidejte časovou dimenzi (tlačítko New...) a u ní vyberte funkci LAST() nebo FIRST().

Erik Eckhardt.
pondělí 15. září 2008
Změna přihlašovací obrazovky do Oracle BI EE / SE-One
Všichni známe standardní obrázek, který se zobrazí, kdykoliv se přihlašujeme do aplikace Oracle Business Intelligence.
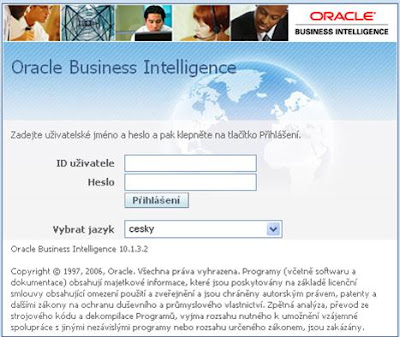
Někdy by však při nasazení u zákazníka vypadalo efektněji, kdyby tento logon byl poněkud jiný, o něco individuálnější.
Například takový:
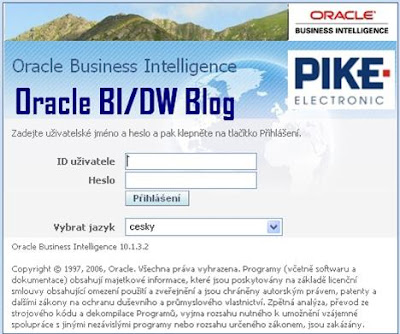
Tento návrh je jen ukázkou pro publikaci na blogu. Váš logon by asi měl být jiný - pochopitelně s logem Vaší firmy a s logem zákazníka, pro kterého je řešení určeno.
Řešení je v podstatě velmi jednoduché. Logon se skládá ze dvou částí – horní a dolní.
Horní část je na následujícím obrázku:

Tento obrázek obsahuje, jak je zřejmé, horní část logonu těsně pod tlačítko „Přihlášení“.
Při spuštění se na něj přenese nápis „Oracle Business Intelligence“ a výzva pro zadání uživatelského jména a hesla včetně příslušných okének.
Myslím, že bohatě postačí, když se výtvarně vyžijeme na této části.
Abych případným zájemcům trochu usnadnil práci, pokusil jsem se obrázek alespoň přibližně proměřit. Výsledkem je následující okótovaný obrázek (kóty jsou pixelech).
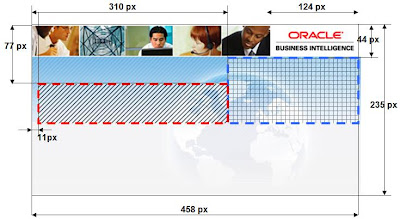
A nyní již je jen otázkou výtvarného nadání, jak kdo s obrázkem naloží. Pro vlastní texty nebo obrázky doporučuji využít vyšrafované oblasti. Můžete pracovat i jinde, ale pak hrozí kolize s texty nebo symboly, které do logonu vkládá samotná aplikace.
Na připojené ukázce jsem si do pravé vyšrafované plochy dovolili umístit logo svého zaměstnavate, do levé plochy nápis „Oracle BI/DW Blog“. Snad mi uživatelé Oracle BI zobrazení v záhlaví původního logonu prominou, že jsem je nahradil panorámatem Západních Tater nad Bystrou dolinou.
A nakonec, soubor, který opravujeme, se jmenuje bglogon.jpg a nachází se v adresáři:
OracleBI\ oc4j_BI\j2ee\home\applications\
analytics\analytics\res\sk_oracle10\b_mozzila4
Jistě není třeba zdůrazňovat, že dříve, než se pustíme do experimentů, je třeba původní soubor řádně zazálohovat.
A protože pracujeme ve webovské vrstvě, je třeba počítat s tím, že se nový logon hned neprojeví. K tomu, aby se objevil, je třeba provést refresh stránky načtené prohlížečem. Až kdyby byl Váš prohlížeč příliš sveřepý a nechtěl nový bglogon zobrazit, je třeba restartovat BI Presentation Server nebo dokonce webovský server.
Příspěvek vytvořil a zaslal Jiří Doubravský - BI/DW konzultant společnosti PIKE Electronic.
Díky!

Někdy by však při nasazení u zákazníka vypadalo efektněji, kdyby tento logon byl poněkud jiný, o něco individuálnější.
Například takový:

Tento návrh je jen ukázkou pro publikaci na blogu. Váš logon by asi měl být jiný - pochopitelně s logem Vaší firmy a s logem zákazníka, pro kterého je řešení určeno.
Řešení je v podstatě velmi jednoduché. Logon se skládá ze dvou částí – horní a dolní.
Horní část je na následujícím obrázku:

Tento obrázek obsahuje, jak je zřejmé, horní část logonu těsně pod tlačítko „Přihlášení“.
Při spuštění se na něj přenese nápis „Oracle Business Intelligence“ a výzva pro zadání uživatelského jména a hesla včetně příslušných okének.
Myslím, že bohatě postačí, když se výtvarně vyžijeme na této části.
Abych případným zájemcům trochu usnadnil práci, pokusil jsem se obrázek alespoň přibližně proměřit. Výsledkem je následující okótovaný obrázek (kóty jsou pixelech).

A nyní již je jen otázkou výtvarného nadání, jak kdo s obrázkem naloží. Pro vlastní texty nebo obrázky doporučuji využít vyšrafované oblasti. Můžete pracovat i jinde, ale pak hrozí kolize s texty nebo symboly, které do logonu vkládá samotná aplikace.
Na připojené ukázce jsem si do pravé vyšrafované plochy dovolili umístit logo svého zaměstnavate, do levé plochy nápis „Oracle BI/DW Blog“. Snad mi uživatelé Oracle BI zobrazení v záhlaví původního logonu prominou, že jsem je nahradil panorámatem Západních Tater nad Bystrou dolinou.
A nakonec, soubor, který opravujeme, se jmenuje bglogon.jpg a nachází se v adresáři:
OracleBI\ oc4j_BI\j2ee\home\applications\
analytics\analytics\res\sk_oracle10\b_mozzila4
Jistě není třeba zdůrazňovat, že dříve, než se pustíme do experimentů, je třeba původní soubor řádně zazálohovat.
A protože pracujeme ve webovské vrstvě, je třeba počítat s tím, že se nový logon hned neprojeví. K tomu, aby se objevil, je třeba provést refresh stránky načtené prohlížečem. Až kdyby byl Váš prohlížeč příliš sveřepý a nechtěl nový bglogon zobrazit, je třeba restartovat BI Presentation Server nebo dokonce webovský server.
Příspěvek vytvořil a zaslal Jiří Doubravský - BI/DW konzultant společnosti PIKE Electronic.
Díky!
pondělí 8. září 2008
Úvod do Oracle Data Integratoru (ODI)
Projekty Datové integrace
Veškerá data v současných organizacích jsou typicky držena v heterogenních datových zdrojích. Pro jejich správné zobrazení v aplikacích a systémech jako je BI, CPM nebo BAM je nutná jejich „úprava“ tj. konsolidace, transformace, čištění atd. Projekty řešící „úpravu“ dat spadají do společné oblasti tzv. Datové Integrace. Zde se můžeme setkat s projekty jako jsou migrace dat ze „staré“ aplikace do nové, replikace dat mezi systémy, Datové sklady a nebo projekty řešící datové a transformační služby pro poskytování dat.
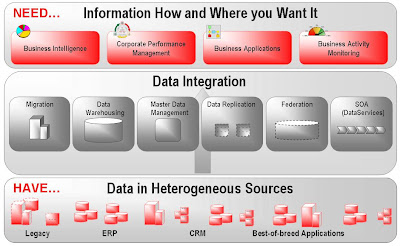
Výzvy a možné problémy Datové integrace
Je jedno jaký integrační projekt řešíme – u všech můžeme narazit na stejné výzvy ze kterých se v budoucnu mohou stát problémy. Mezi ty nejčastější patří:
Zvětšující se objem dat / zmenšující se okno pro jejich přenos
Na začátku projektu jsou odhadnuty přírůstky dat v řádu stovek MB s maximálním oknem pro přenos „do šesti“ hodin. Dle toho, a samozřejmě i dle dalších parametrů, se udělá HW sizing DBMS a ETL Serveru. Postupem času se ze stovek MB stávají jednotky nebo desítky GB a okno „do šesti“ hodin je nedostačující.
Závěr: je nutné začít posilovat HW a to především HW pro ETL Server, který je tím nejslabším místem.
Neintegrované integrace
Nejprve se vybere ETL nástroj, který uspokojí veškeré požadavky pro tvorbu dávkových datových pump. Během nasazení se zjistí, že dávkové přenosy nejsou dostačující a je potřeba přejít na přenosy v reálném čase. Proto se nakoupí jiný nástroj, který umí řešit danou problematiku. No a na konci projektu přijde požadavek na poskytování vyčištěných a zkonsolidovaných dat jiným subjektům a aplikacím pomocí datových služeb – tj. nakoupí se další software.
Závěr: řešíme integrace v neintegrovaném prostředí, tj. jeden integrační projekt = tři různé nástroje pro datovou integraci = neintegrovaná metadata = složitost = vysoké nároky na zdroje a cenu, atd.
Minimální nebo nízká znalost nasazených technologií a principů datové integrace
V současnosti systémoví integrátoři mají odborníky na všechny technologie a veškerou problematiku. Každý zná Oracle, MS SQL, Teradatu, DB2, Informix nebo Sybase a samozřejmě také problematiku Realtime přenosů, dávkových přenosů, práci s velkými objemy dat nebo pomalu se měnící dimenze.
Ale kdo z nás opravdu umí tím nejlepším způsobem naimplementovat CDC (Change Data Capture) na Oracle? Kdo na MS SQL a kdo třeba na DB2? A kdo umí optimálně naimplementovat SCD (Slowly Changing Dimensions) na Teradatě a kdo na Sybase? A nebo kdo z nás umí nejrychleji nahrát gigový soubor do Netezzy nebo SASu a poté jej „mergovat“ se stávajícími daty?
Verze softwarů se mění, a tím přibývají nové vlastnosti, které mohou podstatně ovlivnit výkon celého systému. Například, ten kdo se kdysi potkal s Oraclem a pro chybějící/změněná data využíval INSERT/UPDATE možná ani neví, že existuje MERGE, a nebo ten kdo kdysi používal Materialized Views a Query Rewrite možná neví, že nyní lze automaticky přepisovat SQL dotazy oproti multidimenzionální (MOLAP) kostce, a nebo ten kdo používal Export/Import neví, že jsou k dispozici vysokorychlostní datové pumpy (DataPump), atd.
Závěr: každý nemůže znát všechno a to platí i u technologií a „best practices“ postupů pro jejich nasazení a použití v datové integraci. Vyškolit takového člověka na všechny možné technologie, postupy a principy je nákladné a pravděpodobně nemožné.
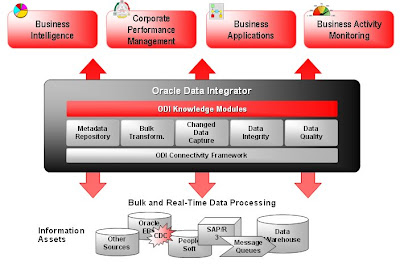
Co je Oracle Data Integrator a jaké jsou jeho výhody
Oracle Data Integrator (ODI – dříve Sunopsis) je integrační platforma pro jakékoli datové integrace (migrace, replikace, datové pumpy pro DWH, synchronizace v MDM nebo datové a transformační služby v rámci SOA) v heterogenním prostředí. Mezi jeho unikátní vlastnosti patří:
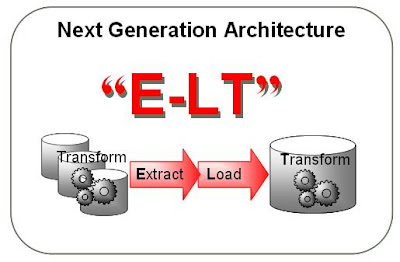
Heterogenní E-LT Architektura
ODI je čistě postaveno na E-LT architektuře, tj. mezi zdrojem a cílem není žádný meziprvek (ETL Server) na který se všechna data přesouvají, kde se pak transformují a poté nahrávají do cíle. Klasický ETL Server bývá tím nejslabším místem v řetězci systémů zapojených do datové integrace. Jestliže investujete své peníze do licencí za DBMS systém a do našlapaného HW, pak by byla škoda, aby výkon této investice kazil nějaký meziprvek (o výhodách E-LT a rozdílu oproti ETL architektuře jsme již psali zde).
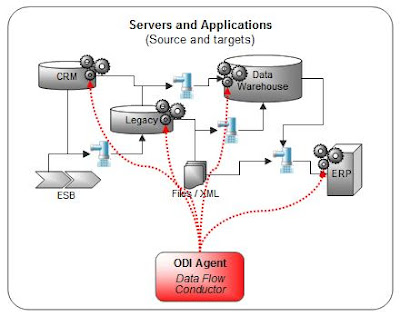
ODI pro svou práci během extraktů, loadů a transformací dat vždy využívá nativní funkcionalitu (specifické SQL, bulk operace, bulk utility, API, atd.) zdrojové nebo cílové DBMS platformy.
ODI automaticky vygeneruje optimalizovaný nativní kód pro používané DBMS a pak pouze orchestruje jeho spouštění (transformace jsou vždy vykonávány samotnými DBMS – důvodem je fakt, že v současnosti jsou DBMS systémy tou nejlépe a nejvíce optimalizovanou platformou na světě, která je vhodná pro manipulaci s velkými objemy dat).
Samotnou orchestraci provádí ODI Agent, který může být nakonfigurován pro „load balancing“ (více současně běžících Agentů), a který může běžet na jakékoli platformě podporující JAVU (na zdroji, cíli nebo kdekoli jinde).
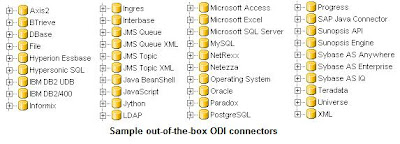
Z pohledu heterogennosti jsou s ODI dodávány "out-of-the-box" konektory do různých technologií a aplikací. Celý systém je otevřen - je možné současné konektory upravovat a samozřejmě přidávat a definovat své vlastní.
Aktivní integrace
ODI umožňuje řešit jakékoli typy datové integrace. Od standardních dávkových přenosů (Data-oriented Integration), přes přenosy v reálném čase (Event-oriented Integration) až po přenosy pomocí služeb (Service-oriented Integration). Pro všechny typy integrací ODI zajišťuje stejné uživatelské prostředí a samozřejmě jedny metadata.
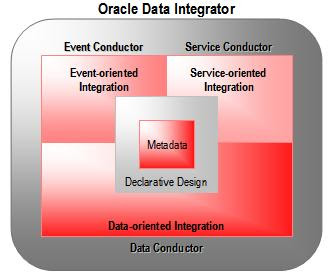
Event-oriented Integration
Do Event-oriented Integration patří integrace s Message-oriented middleware (MOM) systémy a s Enterprise service bus (ESB) systémy různých dodavatelů. ODI umožňuje napojení na JMS Queue a na JMS Topic. MOM/ESB systém může být jak na straně zdroje, tak i na straně cíle a během integrace mohou být data z MOM/ESB transformována spolu s daty z jiných systémů (databází, aplikací, WS, XML, Files, ...).
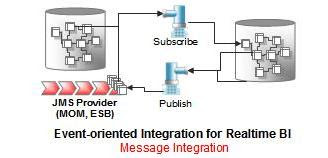
Hlavní silou ODI není posílání zpráv, ale přenosy a transformace velkých objemů dat. V případě, že je potřeba vše dělat v reálném čase pak ODI nabízí funkcionalitu zachytávání změn, tzn. Change Data Capture (CDC).
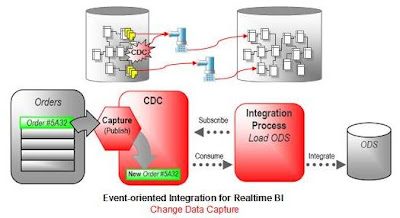
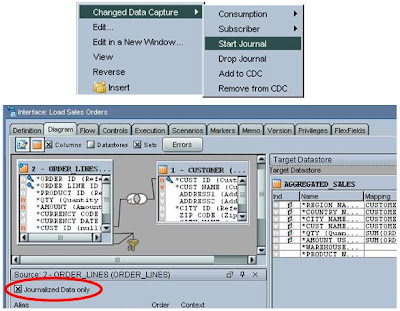
V ODI je pro CDC připraven framework, který umožňuje CDC jednoduše naimplementovat pomocí Triggerů (dostupné na většině DBMS), nebo pomocí nativního CDC DBMS platformy (jako např. Oracle, IBM DB2, MS SQL, VSAM, Adabas, ...), a nebo využití CDC třetích stran, jako např. Attunity Stream (certifikováno jak s ODI tak i s Oracle Warehouse Builderem).
Service-oriented Integration
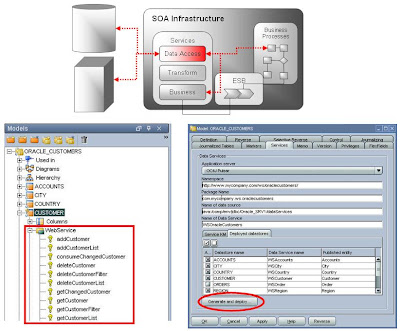
Do Service-oriented Integration samozřejmě patří Web Services (WS). Aniž by jste uměli programovat, ODI pro Vás umí vygenerovat dva typy WS, a to Data Access Services a Data Transformation Services.
1/ Data Access Services
Nad jakoukoli DBMS Vám ODI vygeneruje sadu WS pro zpřístupnění a manipulaci s daty včetně řízení CDC a kontroly datové kvality. Jedním stisknutím tlačítka jsou veškeré služby vygenerovány a automatiky naimplementovány do Vaší SOA Infrastruktury (J2EE + Axis2), takže je ihned můžete začít využívat:
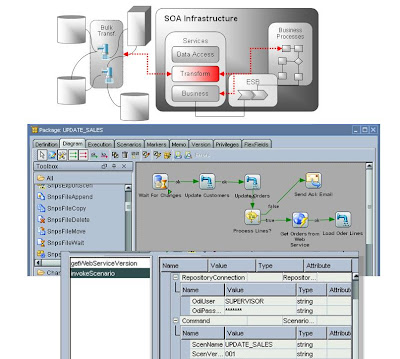
2/ Data Transformation Services
Mnohem zajímavější a z pohledu integrace velkých objemů dat i důležitější jsou Data Transformation Services. V ODI navrhnete integrační/transformační procesy s využitím veškerých nativních funkcionalit (specifické SQL, bulk operace, CDC, bulk utility, API, atd.) použitých DBMS. Poté vytvoříte schéma závislostí/posloupností procesů včetně ošetření chybových stavů, tj. workflow, a nad tím vším Vám ODI vygeneruje Webovou službu pomocí které vše můžete řídit.
Výhodou je, že veškeré transformace a manipulace s daty jsou stále vykonávány na úrovni DBMS platforem a WS jsou zde použity pouze pro řízení (tj. data nejsou přesouvána a transformována na middleware, čímž by se degradoval výkon samotné integrace).
Deklarativní návrh
Představte si příkaz SELECT. Když potřebujete získat informace z databáze tak definujete CO CHCETE – tj. SELECT jaké sloupce, FROM z jakých tabulek, WHERE s jakou podmínkou. Samotný DBMS engine s pomocí Cost based optimalizátoru a statistik vygeneruje tu nejlepší „best practice“ cestu jak daný SELECT zpracovat a vrátit co nejrychleji požadované informace. Psaní SELECTů je de facto deklarativní návrh – říkáte co chcete a databáze na základě statistik ví jak to optimálně provést.
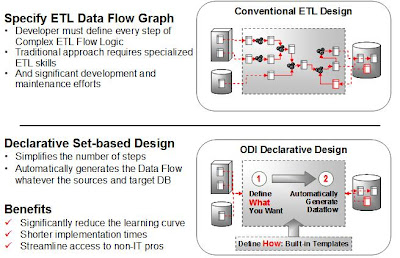
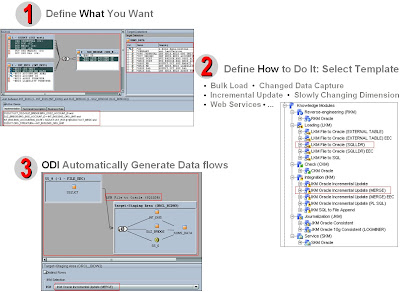
ODI používá stejný princip – tj. vývojář definuje „Co chce udělat“ a ODI podle „best practices“ postupů pro různé oblasti datové integrace a použité technologii vygeneruje požadovaný kód pro load a transformaci dat.
Jednoduchý příklad, potřebuji integrovat data z textového souboru se stávajícími daty uloženými v Oracle. Chci to provést co nejrychleji a inkrementálně (tj. nové záznamy přidat, stávající aktualizovat, ostatní ponechat). Bohužel nemám potřebné znalosti cílové technologie - nevím jak nejlépe nahrát soubor do databáze, nevím jak se definuje „Control file“ pro SQL Loader nebo External Table a ani jak se používají. Neznám možnosti Oracle pro inkrementální přihrávání dat.
Vývojář nemusí být „guru“ na veškeré technologie a oblasti integrace - ODI díky Deklarativnímu návrhu a „Knowledge“ modulům mu s tím pomůže. Stačí když vývojář:
Znalostní (Knowledge) moduly
V současné době skoro na všechno existují „best practices“ postupy. To platí i pro datovou integraci a dostupné technologie. ODI obsahuje více jak 150 hotových „best practices“ postupů/šablon (tzv. Knowledge moduly) pro různé oblasti datové integrace a pro různé technologie včetně BTrieve, DBase, File, Hyperion, Hypersonic SQL, IBM DB2, Informix, Ingres, Interbase, JMS, LDAP, MS Excel/Access/SQL Server, MySQL, Netezza, Oracle, Paradox, PostgreSQL, Progress, SAP, Sybase, Teradata, XML a dalších.
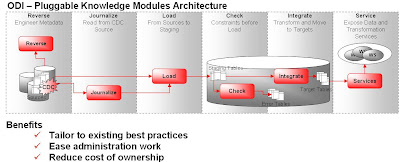
Moduly se dělí do šesti oblastí:
Knowledge Moduly (KM) mohou být:
KM nemusí být vytvořen pouze v jedné technologii. Může obsahovat jakýkoli jazyk databáze, Shell skripty, Javu, Jython, atd.
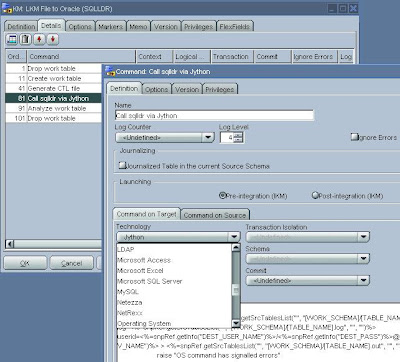
Například: Load File to Oracle pomocí SQLLDR, používá funkce Oracle databáze pro založení/zrušení dočasné tabulky (CREATE, ANALYZE, DROP), Sunopsis API pro vygenerování a uložení řídícího souboru pro SQLLDR na disk, a dále pak pomocí Jythonu volá Oracle utilitu SQLLDR, která nahraje textový souboru do databáze.
Z důvodu opakovaného použití by měli KM obsahovat „placeholdery“ se Sunopsis API, které jsou při spuštění nahrazeny fyzickými jmény tabulek, sloupců, schémat, výrazů nebo jiných metadata objektů a atributů.
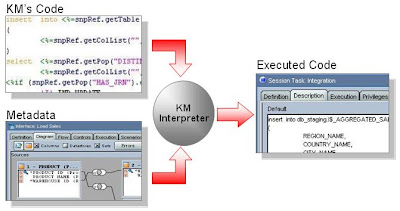
Veškeré dodávané Knowledge Moduly jsou otevřené, tj. každý se do nich může podívat, upravit je nebo si vytvářet své vlastní a ty pak sdílet s ostatními – mohou se pak dostat i do další verze Oracle Data Integratoru.

ODI v Oracle
ODI je strategická platforma pro veškeré datové integrace v heterogenním prostředí. Proto se s ním můžete setkat i v dalších Oracle technologiích a aplikacích, jako jsou:
Příští články o ODI budou věnovány tipům a trikům.
Erik Eckhardt.
Veškerá data v současných organizacích jsou typicky držena v heterogenních datových zdrojích. Pro jejich správné zobrazení v aplikacích a systémech jako je BI, CPM nebo BAM je nutná jejich „úprava“ tj. konsolidace, transformace, čištění atd. Projekty řešící „úpravu“ dat spadají do společné oblasti tzv. Datové Integrace. Zde se můžeme setkat s projekty jako jsou migrace dat ze „staré“ aplikace do nové, replikace dat mezi systémy, Datové sklady a nebo projekty řešící datové a transformační služby pro poskytování dat.

Výzvy a možné problémy Datové integrace
Je jedno jaký integrační projekt řešíme – u všech můžeme narazit na stejné výzvy ze kterých se v budoucnu mohou stát problémy. Mezi ty nejčastější patří:
Zvětšující se objem dat / zmenšující se okno pro jejich přenos
Na začátku projektu jsou odhadnuty přírůstky dat v řádu stovek MB s maximálním oknem pro přenos „do šesti“ hodin. Dle toho, a samozřejmě i dle dalších parametrů, se udělá HW sizing DBMS a ETL Serveru. Postupem času se ze stovek MB stávají jednotky nebo desítky GB a okno „do šesti“ hodin je nedostačující.
Závěr: je nutné začít posilovat HW a to především HW pro ETL Server, který je tím nejslabším místem.
Neintegrované integrace
Nejprve se vybere ETL nástroj, který uspokojí veškeré požadavky pro tvorbu dávkových datových pump. Během nasazení se zjistí, že dávkové přenosy nejsou dostačující a je potřeba přejít na přenosy v reálném čase. Proto se nakoupí jiný nástroj, který umí řešit danou problematiku. No a na konci projektu přijde požadavek na poskytování vyčištěných a zkonsolidovaných dat jiným subjektům a aplikacím pomocí datových služeb – tj. nakoupí se další software.
Závěr: řešíme integrace v neintegrovaném prostředí, tj. jeden integrační projekt = tři různé nástroje pro datovou integraci = neintegrovaná metadata = složitost = vysoké nároky na zdroje a cenu, atd.
Minimální nebo nízká znalost nasazených technologií a principů datové integrace
V současnosti systémoví integrátoři mají odborníky na všechny technologie a veškerou problematiku. Každý zná Oracle, MS SQL, Teradatu, DB2, Informix nebo Sybase a samozřejmě také problematiku Realtime přenosů, dávkových přenosů, práci s velkými objemy dat nebo pomalu se měnící dimenze.
Ale kdo z nás opravdu umí tím nejlepším způsobem naimplementovat CDC (Change Data Capture) na Oracle? Kdo na MS SQL a kdo třeba na DB2? A kdo umí optimálně naimplementovat SCD (Slowly Changing Dimensions) na Teradatě a kdo na Sybase? A nebo kdo z nás umí nejrychleji nahrát gigový soubor do Netezzy nebo SASu a poté jej „mergovat“ se stávajícími daty?
Verze softwarů se mění, a tím přibývají nové vlastnosti, které mohou podstatně ovlivnit výkon celého systému. Například, ten kdo se kdysi potkal s Oraclem a pro chybějící/změněná data využíval INSERT/UPDATE možná ani neví, že existuje MERGE, a nebo ten kdo kdysi používal Materialized Views a Query Rewrite možná neví, že nyní lze automaticky přepisovat SQL dotazy oproti multidimenzionální (MOLAP) kostce, a nebo ten kdo používal Export/Import neví, že jsou k dispozici vysokorychlostní datové pumpy (DataPump), atd.
Závěr: každý nemůže znát všechno a to platí i u technologií a „best practices“ postupů pro jejich nasazení a použití v datové integraci. Vyškolit takového člověka na všechny možné technologie, postupy a principy je nákladné a pravděpodobně nemožné.
Co je Oracle Data Integrator a jaké jsou jeho výhody
Oracle Data Integrator (ODI – dříve Sunopsis) je integrační platforma pro jakékoli datové integrace (migrace, replikace, datové pumpy pro DWH, synchronizace v MDM nebo datové a transformační služby v rámci SOA) v heterogenním prostředí. Mezi jeho unikátní vlastnosti patří:
- Heterogenní E-LT Architektura – zajišťuje vysoký výkon a škálovatelnost datových pump v heterogenním prostředí
- Aktivní integrace – integrované řešení pro jakékoliv projekty z oblasti datové integrace
- Deklarativní návrh – snižuje nároky na vývojáře a jejich znalosti
- Znalostní (Knowledge) moduly – „Best practices“ řešení pro různé oblasti datové integrace a použité technologie

Heterogenní E-LT Architektura
ODI je čistě postaveno na E-LT architektuře, tj. mezi zdrojem a cílem není žádný meziprvek (ETL Server) na který se všechna data přesouvají, kde se pak transformují a poté nahrávají do cíle. Klasický ETL Server bývá tím nejslabším místem v řetězci systémů zapojených do datové integrace. Jestliže investujete své peníze do licencí za DBMS systém a do našlapaného HW, pak by byla škoda, aby výkon této investice kazil nějaký meziprvek (o výhodách E-LT a rozdílu oproti ETL architektuře jsme již psali zde).

ODI pro svou práci během extraktů, loadů a transformací dat vždy využívá nativní funkcionalitu (specifické SQL, bulk operace, bulk utility, API, atd.) zdrojové nebo cílové DBMS platformy.
ODI automaticky vygeneruje optimalizovaný nativní kód pro používané DBMS a pak pouze orchestruje jeho spouštění (transformace jsou vždy vykonávány samotnými DBMS – důvodem je fakt, že v současnosti jsou DBMS systémy tou nejlépe a nejvíce optimalizovanou platformou na světě, která je vhodná pro manipulaci s velkými objemy dat).
Samotnou orchestraci provádí ODI Agent, který může být nakonfigurován pro „load balancing“ (více současně běžících Agentů), a který může běžet na jakékoli platformě podporující JAVU (na zdroji, cíli nebo kdekoli jinde).

Z pohledu heterogennosti jsou s ODI dodávány "out-of-the-box" konektory do různých technologií a aplikací. Celý systém je otevřen - je možné současné konektory upravovat a samozřejmě přidávat a definovat své vlastní.

Aktivní integrace
ODI umožňuje řešit jakékoli typy datové integrace. Od standardních dávkových přenosů (Data-oriented Integration), přes přenosy v reálném čase (Event-oriented Integration) až po přenosy pomocí služeb (Service-oriented Integration). Pro všechny typy integrací ODI zajišťuje stejné uživatelské prostředí a samozřejmě jedny metadata.

Event-oriented Integration
Do Event-oriented Integration patří integrace s Message-oriented middleware (MOM) systémy a s Enterprise service bus (ESB) systémy různých dodavatelů. ODI umožňuje napojení na JMS Queue a na JMS Topic. MOM/ESB systém může být jak na straně zdroje, tak i na straně cíle a během integrace mohou být data z MOM/ESB transformována spolu s daty z jiných systémů (databází, aplikací, WS, XML, Files, ...).

Hlavní silou ODI není posílání zpráv, ale přenosy a transformace velkých objemů dat. V případě, že je potřeba vše dělat v reálném čase pak ODI nabízí funkcionalitu zachytávání změn, tzn. Change Data Capture (CDC).

V ODI je pro CDC připraven framework, který umožňuje CDC jednoduše naimplementovat pomocí Triggerů (dostupné na většině DBMS), nebo pomocí nativního CDC DBMS platformy (jako např. Oracle, IBM DB2, MS SQL, VSAM, Adabas, ...), a nebo využití CDC třetích stran, jako např. Attunity Stream (certifikováno jak s ODI tak i s Oracle Warehouse Builderem).

Service-oriented Integration
Do Service-oriented Integration samozřejmě patří Web Services (WS). Aniž by jste uměli programovat, ODI pro Vás umí vygenerovat dva typy WS, a to Data Access Services a Data Transformation Services.
1/ Data Access Services
Nad jakoukoli DBMS Vám ODI vygeneruje sadu WS pro zpřístupnění a manipulaci s daty včetně řízení CDC a kontroly datové kvality. Jedním stisknutím tlačítka jsou veškeré služby vygenerovány a automatiky naimplementovány do Vaší SOA Infrastruktury (J2EE + Axis2), takže je ihned můžete začít využívat:
add[DATASTRE_NAME] add[DATASTRE_NAME]List delete[DATASTRE_NAME] delete[DATASTRE_NAME]Filter delete[DATASTRE_NAME]List get[DATASTRE_NAME] get[DATASTRE_NAME]Filter get[DATASTRE_NAME]List update[DATASTRE_NAME] update[DATASTRE_NAME]Filter update[DATASTRE_NAME]List consumeChanged[DATASTRE_NAME] getChanged[DATASTRE_NAME]

2/ Data Transformation Services
Mnohem zajímavější a z pohledu integrace velkých objemů dat i důležitější jsou Data Transformation Services. V ODI navrhnete integrační/transformační procesy s využitím veškerých nativních funkcionalit (specifické SQL, bulk operace, CDC, bulk utility, API, atd.) použitých DBMS. Poté vytvoříte schéma závislostí/posloupností procesů včetně ošetření chybových stavů, tj. workflow, a nad tím vším Vám ODI vygeneruje Webovou službu pomocí které vše můžete řídit.
Výhodou je, že veškeré transformace a manipulace s daty jsou stále vykonávány na úrovni DBMS platforem a WS jsou zde použity pouze pro řízení (tj. data nejsou přesouvána a transformována na middleware, čímž by se degradoval výkon samotné integrace).

Deklarativní návrh
Představte si příkaz SELECT. Když potřebujete získat informace z databáze tak definujete CO CHCETE – tj. SELECT jaké sloupce, FROM z jakých tabulek, WHERE s jakou podmínkou. Samotný DBMS engine s pomocí Cost based optimalizátoru a statistik vygeneruje tu nejlepší „best practice“ cestu jak daný SELECT zpracovat a vrátit co nejrychleji požadované informace. Psaní SELECTů je de facto deklarativní návrh – říkáte co chcete a databáze na základě statistik ví jak to optimálně provést.

Jednoduchý příklad, potřebuji integrovat data z textového souboru se stávajícími daty uloženými v Oracle. Chci to provést co nejrychleji a inkrementálně (tj. nové záznamy přidat, stávající aktualizovat, ostatní ponechat). Bohužel nemám potřebné znalosti cílové technologie - nevím jak nejlépe nahrát soubor do databáze, nevím jak se definuje „Control file“ pro SQL Loader nebo External Table a ani jak se používají. Neznám možnosti Oracle pro inkrementální přihrávání dat.
Vývojář nemusí být „guru“ na veškeré technologie a oblasti integrace - ODI díky Deklarativnímu návrhu a „Knowledge“ modulům mu s tím pomůže. Stačí když vývojář:
Navrhne co chce dělat, tj. mapování/integraci mezi objekty zdroje a cíle Vybere „best practice“ postup/šablonu jak to celé naimplementovat (např. SQLLoader pro load souboru do databáze a MERGE pro transformaci se stávajícími daty) ODI automaticky vygeneruje požadovanou datovou pumpu

V současné době skoro na všechno existují „best practices“ postupy. To platí i pro datovou integraci a dostupné technologie. ODI obsahuje více jak 150 hotových „best practices“ postupů/šablon (tzv. Knowledge moduly) pro různé oblasti datové integrace a pro různé technologie včetně BTrieve, DBase, File, Hyperion, Hypersonic SQL, IBM DB2, Informix, Ingres, Interbase, JMS, LDAP, MS Excel/Access/SQL Server, MySQL, Netezza, Oracle, Paradox, PostgreSQL, Progress, SAP, Sybase, Teradata, XML a dalších.

Reverse
- obsahuje „best practices“ jak načítat metadata (reverse engineering) z různých systémů / aplikací / technologiíJournalize
- obsahuje „best practices“ jak implementovat Change Data Capture na různých technologiíLoad
- obsahuje „best practices“ jak nejrychleji nahrávat data z heterogenních zdrojů (různé DBMS, File, XML, JMS, ...) do heterogenních cílůCheck
- obsahuje „best practices“ jak zajišťovat integritu a čistotu dat pro různé technologieIntegrate
- obsahuje „best practices“ jak nejoptimálněji provádět transformace dat na různých technologiíService
- obsahuje „best practices“ jak vytvářet Webové služby nad různými DBMS
Knowledge Moduly (KM) mohou být:
obecné, tj. v případě DBMS fungují pro jakoukoli „ISO-92 compliant“ databázi (např. "Load File to SQL" nebo "SQL to File Append") specifické pro určitou technologii, tj. využívají specifické SQL, funkce, bulk operace, utility, API, atd. dané technologie (např. "Load File to Oracle with EXTERNAL TABLE")
KM nemusí být vytvořen pouze v jedné technologii. Může obsahovat jakýkoli jazyk databáze, Shell skripty, Javu, Jython, atd.
Například: Load File to Oracle pomocí SQLLDR, používá funkce Oracle databáze pro založení/zrušení dočasné tabulky (CREATE, ANALYZE, DROP), Sunopsis API pro vygenerování a uložení řídícího souboru pro SQLLDR na disk, a dále pak pomocí Jythonu volá Oracle utilitu SQLLDR, která nahraje textový souboru do databáze.



ODI v Oracle
ODI je strategická platforma pro veškeré datové integrace v heterogenním prostředí. Proto se s ním můžete setkat i v dalších Oracle technologiích a aplikacích, jako jsou:
Oracle BI EE Plus
ODI je zde pro tvorbu a plnění DWHOracle BI Applications
ODI obsahuje předpřipravené datové pumpy k plnění Enterprise DWH pro analytické aplikaceOracle SOA Suite
ODI a jeho transformační/datové služby pro dávkové přenosy a zpracování velkých objemů dat jako součást business procesů řízených pomocí Oracle BPEL
ODI pro realtimeové plnění „Active Data Cache“ pro Oracle Business Activity Monitoring (BAM)Oracle EPM (Hyperion Planning, Financial Management a Essbase)
ODI pro extrahování/tvorbu metadat, extrahování/nahrávání dimenzí, extrahování/nahrávání dat, plnění/obnovu kostek, konsolidaci a kalkulaceOracle Warehouse Builder 11gR2
Zahrnutí ODI funkcionality do OWB
Příští články o ODI budou věnovány tipům a trikům.
Erik Eckhardt.
středa 3. září 2008
Hlasování o nejlepší BI Dashboard v letní soutěži s Oracle BI
Vážení přátelé,
děkujeme vám všem, kteří jste se zúčastnili "Letní soutěže s Oracle Business Intelligence". Z celkového počtu 40-ti zaregistrovaných účastníků jich 6 splnilo podmínky pro účast v soutěži o ceny.
Samotné hlasování o "Nejlepší BI Dashboard" probíhá formou ankety, kterou najdete na pravé straně BI /DW Blogu. Stačí když ze seznamu soutěžících BI Dashboardů (najdete je níže) vyberete ten nejlepší a klikem v anketě mu dáte svůj hlas (hlasovat můžete do 5.10.2008).
A jaká byla odezva zúčastněných na Oracle BI? Hodnotilo se jako ve škole 1-nejlepší, 5-nejhorší a výsledné hodnoty jsou zprůměrované:
Oracle BI/DW team.
Soutěžící BI Dashboardy o ceny
#1 - Executive Dashboard
#2 - DK Dashboard
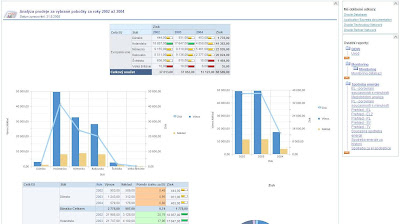
#3 - Analýza zisku
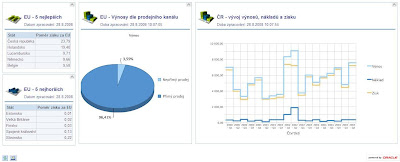
#4 - Regionální analýza prodeje
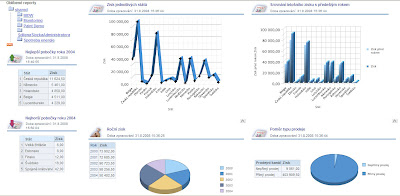
#5 - Panel CFO
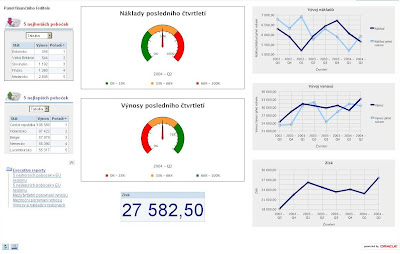
#6 - LogisticsLtd
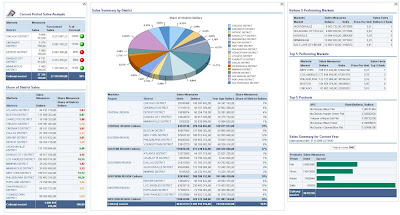
děkujeme vám všem, kteří jste se zúčastnili "Letní soutěže s Oracle Business Intelligence". Z celkového počtu 40-ti zaregistrovaných účastníků jich 6 splnilo podmínky pro účast v soutěži o ceny.
Samotné hlasování o "Nejlepší BI Dashboard" probíhá formou ankety, kterou najdete na pravé straně BI /DW Blogu. Stačí když ze seznamu soutěžících BI Dashboardů (najdete je níže) vyberete ten nejlepší a klikem v anketě mu dáte svůj hlas (hlasovat můžete do 5.10.2008).
A jaká byla odezva zúčastněných na Oracle BI? Hodnotilo se jako ve škole 1-nejlepší, 5-nejhorší a výsledné hodnoty jsou zprůměrované:
- 1,5 - Intuitivnost tvorby reportů/analýz
- 1,2 - Intuitivnost tvorby BI Dashboardu
- 1,2 - Celkový dojem z Oracle BI
Oracle BI/DW team.
Soutěžící BI Dashboardy o ceny
#1 - Executive Dashboard

#2 - DK Dashboard

#3 - Analýza zisku

#4 - Regionální analýza prodeje

#5 - Panel CFO

#6 - LogisticsLtd

pondělí 1. září 2008
Roadmapa pro Oracle Warehouse Builder
Začátkem července byla uvolněna roadmapa pro Oracle Warehouse Builder. Dokument je dostupný zde.
Přihlásit se k odběru:
Příspěvky (Atom)