pondělí 22. prosince 2008

čtvrtek 18. prosince 2008
ODI - Integrace, transformace, mapování
V minulém díle jsme na základě zdrojového modelu vygenerovali model cílový. Nyní máme k dispozici zdroj i cíl a tudíž můžeme přistoupit k samotné integraci.
Podívejte se na video ukazující "step-by-step" postup jak v ODI provádět datové integrace, transformace, mapování.
jak v ODI provádět datové integrace, transformace, mapování.
Příště si ukážeme pokročilou funkcionalitu ODI, jako je Data Lineage, Workflow, Business pravidla pro datovou kvalitu nebo Webové služby.
Peter Hora (Semanta).
Podívejte se na video ukazující "step-by-step" postup
jak v ODI provádět datové integrace, transformace, mapování.Příště si ukážeme pokročilou funkcionalitu ODI, jako je Data Lineage, Workflow, Business pravidla pro datovou kvalitu nebo Webové služby.
Peter Hora (Semanta).
pondělí 15. prosince 2008
Zkušenosti s vytvářením, používaním a výkonností vlastních ukazatelů
V následujícím příspěvku uvádím zkušenosti s vytvářením, používaním a výkonností vlastních ukazatelů (počítaných sloupců). Příspěvek navazuje na článek Dva způsoby jak definovat vlastní výpočty (ukazatele) v Business modelu.
Vlastní ukazatel (např. početní operace nad hodnotami dvou sloupců) lze definovat následujícími způsoby:
1. Při návrhu reportu
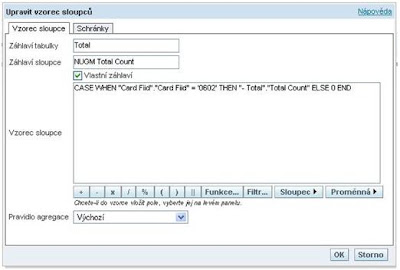
2. Pomocí metadat použitím logických sloupců
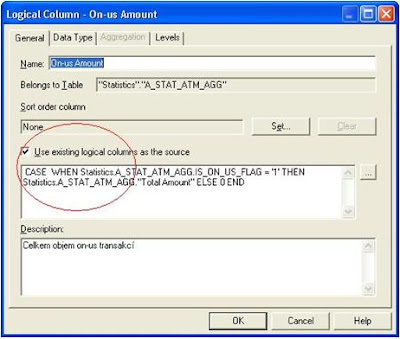
Ukázka výsledného dotazu:
WITH sawith0 AS
(SELECT DISTINCT t17101.is_on_us_flag AS c1, t1339.date_dt AS c2
FROM l1_owner.d_date t1339, l2_owner.a_stat_atm_agg t17101
WHERE (t1339.date_dt = t17101.audit_id)),
sawith1 AS
(SELECT SUM (t17101.amt_amt) AS c1, t1339.date_dt AS c2
FROM l1_owner.d_date t1339, l2_owner.a_stat_atm_agg t17101
WHERE (t1339.date_dt = t17101.audit_id)
GROUP BY t1339.date_dt)
SELECT DISTINCT CASE
WHEN sawith0.c2 IS NOT NULL
THEN sawith0.c2
WHEN sawith1.c2 IS NOT NULL
THEN sawith1.c2
END AS c1,
CASE
WHEN sawith0.c1 = '1'
THEN sawith1.c1
ELSE 0
END AS c2
FROM sawith0 FULL OUTER JOIN sawith1 ON sawith0.c2 = sawith1.c2
ORDER BY c1
3. Pomocí metadat použitím fyzických sloupců
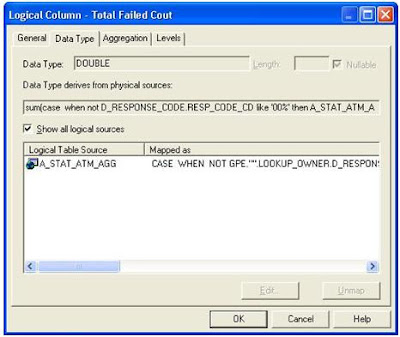
Ukázka výsledného dotazu:
SELECT t1339.date_dt AS c1,
SUM
(CASE
WHEN NOT t5199.resp_code_cd LIKE '00%'
THEN t17101.trn_cnt
ELSE 0
END
) AS c2
FROM l1_owner.d_date t1339,
lookup_owner.d_response_code t5199,
l2_owner.a_stat_atm_agg t17101
WHERE ( t1339.date_dt = t17101.audit_id
AND t5199.response_code_id = t17101.resp_cde_id
)
GROUP BY t1339.date_dt
ORDER BY c1
Závěr
Z výše uvedených informací vyplývá mé doporučení - pro definici vlastních ukazatelů používat v maximální míře fyzických sloupců:
Vlastní ukazatel (např. početní operace nad hodnotami dvou sloupců) lze definovat následujícími způsoby:
- Přímo při návrhu reportu
- Pomocí metadat použitím logických sloupců
- Pomocí metadat použitím fyzických sloupců
1. Při návrhu reportu
- Jednoduché a rychlé nastavení
- Vhodné při neopakovaném používání ukazatele (ukazatel je dostupný pouze v reportu kde je vytvořen)
- Samotný výpočet je prováděn nad agregovanými nebo detailními ukazateli (záleží na tom zda výchozí ukazatel měl v metadata vrstvě přednastavenu agregační funkci)
- Při nesprávném pochopení ukazatele z něhož se vychází a použití výpočetní funkce se může dojít k chybnému/nechtěnému výsledku (např. zprůměrovat již součtované ukazatele nebo viz. zde)
- Doporučuji používat pouze v případě, kdy zdrojové sloupce jsou také obsahem reportu
- V případě použití sloupců, které nejsou obsahem reportu má fyzický dotaz vysoký COST, který může narůst až o 6 řádů
- Tento způsob využijí spíše koncoví uživatelé pro Ad-hoc potřebu

2. Pomocí metadat použitím logických sloupců
- Výraz může odkazovat na sloupce/ukazatele v dané logické tabulce (i z více zdrojů)
- Nejprve je prováděna agregace, a pak výpočet nového sloupce což může ovlivnit správnost / nesprávnost výsledků – více viz. zde
- Pokud je odkazovaný sloupec obsahem reportu, tak je vše OK. Pokud není, pak fyzický dotaz má vysoký COST
- Ukazatel je pojmenován a delegován až do prezentační vrstvy – je možné jej opakovaně používat

Ukázka výsledného dotazu:
WITH sawith0 AS
(SELECT DISTINCT t17101.is_on_us_flag AS c1, t1339.date_dt AS c2
FROM l1_owner.d_date t1339, l2_owner.a_stat_atm_agg t17101
WHERE (t1339.date_dt = t17101.audit_id)),
sawith1 AS
(SELECT SUM (t17101.amt_amt) AS c1, t1339.date_dt AS c2
FROM l1_owner.d_date t1339, l2_owner.a_stat_atm_agg t17101
WHERE (t1339.date_dt = t17101.audit_id)
GROUP BY t1339.date_dt)
SELECT DISTINCT CASE
WHEN sawith0.c2 IS NOT NULL
THEN sawith0.c2
WHEN sawith1.c2 IS NOT NULL
THEN sawith1.c2
END AS c1,
CASE
WHEN sawith0.c1 = '1'
THEN sawith1.c1
ELSE 0
END AS c2
FROM sawith0 FULL OUTER JOIN sawith1 ON sawith0.c2 = sawith1.c2
ORDER BY c1
3. Pomocí metadat použitím fyzických sloupců
- Výraz může odkazovat na sloupce v připojených fyzických tabulkách (source)
- Nejprve je prováděn výpočet, a pak agregace nového sloupce což může ovlivnit správnost / nesprávnost výsledků – více viz. zde
- „Nepatrný“ COST fyzického dotazu a to ať jsou nebo nejsou zdrojové sloupce použity v reportu
- Ukazatel je pojmenován a delegován až do prezentační vrstvy – je možné jej opakovaně používat

Ukázka výsledného dotazu:
SELECT t1339.date_dt AS c1,
SUM
(CASE
WHEN NOT t5199.resp_code_cd LIKE '00%'
THEN t17101.trn_cnt
ELSE 0
END
) AS c2
FROM l1_owner.d_date t1339,
lookup_owner.d_response_code t5199,
l2_owner.a_stat_atm_agg t17101
WHERE ( t1339.date_dt = t17101.audit_id
AND t5199.response_code_id = t17101.resp_cde_id
)
GROUP BY t1339.date_dt
ORDER BY c1
Závěr
Z výše uvedených informací vyplývá mé doporučení - pro definici vlastních ukazatelů používat v maximální míře fyzických sloupců:
- Ukazatel je delegován až do prezentační vrstvy, takže jej lze opakovaně použít samotnými koncovými uživateli
- Není limitováno dalším způsobem použití (viz koncové dotazy)
- Nižší COST fyzického dotazu
Miroslav Petr (Adastra).
čtvrtek 11. prosince 2008
ODI - Založení cílového datového modelu (migrace modelů mezi různými technologiemi)
V předchozí části jsme v ODI pomocí funkcionality reverse-engineering načetli zdrojový datový model, ale cílový dat. model stále chybí.
Podívejte se na video ukazující "step-by-step" postup:
Příští díl bude o tom jak v ODI provádět samotné datové integrace, transformace, mapování mezi výše uvedenými modely.
Peter Hora (Semanta).
Podívejte se na video ukazující "step-by-step" postup:
- Jak lze v ODI na základě zdrojového dat. modelu vytvořit model cílový (neboli jak migrovat dat. modely mezi různými technologiemi)
- Jak v ODI vygenerovat a spustit databázové scripty pro fyzickou implementaci cílového dat. modelu
Příští díl bude o tom jak v ODI provádět samotné datové integrace, transformace, mapování mezi výše uvedenými modely.
Peter Hora (Semanta).
pondělí 8. prosince 2008
Současné zobrazení N nejlepších a N nejhorších
Na posledním školení jsem zákazníkům demonstroval příklad na výpis Top N a Ostatní. Padl dotaz, zda by šlo do téže sestavy vypsat současně "N" nejlepších a "N" nejhorších. Níže najdete řešení provedené nad demonstračními daty "Paint":
1. Vyberte Jeden sloupec s dimenzí a jeden faktový
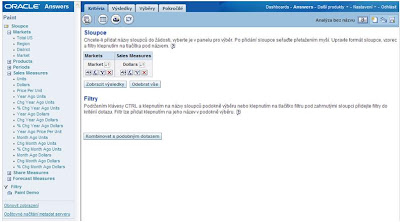
2. Stejný faktový sloupec přidejte ještě 3x
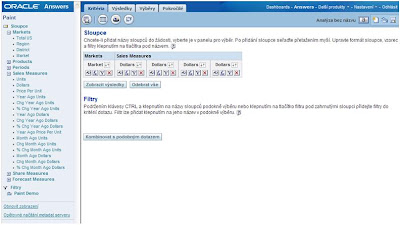
3. Jeho druhý výskyt upravte (Upravit sloupec)
4. Na témže sloupci nastavte třídění
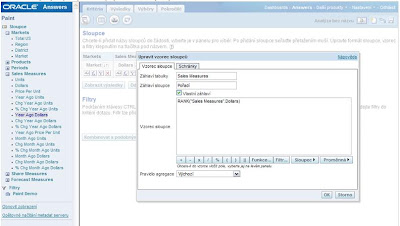
5. Následující sloupec bude sloužit pro určení toho, které z řádků patří mezi „Nejlepších 5“ a které mezi „Nejhorších 5“. Zvolte opět „Upravit sloupec“ (tlačítko fx) a použijte následující CASE příkaz:
CASE WHEN RANK("Sales Measures".Dollars) <= 5 THEN Markets.Market WHEN RANK("Sales Measures".Dollars) > MAX(RANK("Sales Measures".Dollars))-5 THEN Markets.Market ELSE 'Ostatní' END
V takto upraveném sloupci budou zobrazeny názvy poboček (hodnot dimenze) v případě, že jsou mezi prvními nebo posledními 5ti. V opačném případě bude v tomto sloupci hodnota „Ostatní“
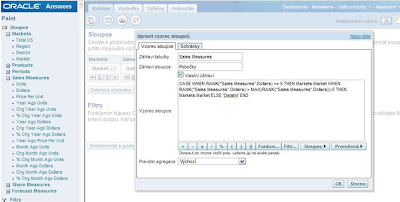
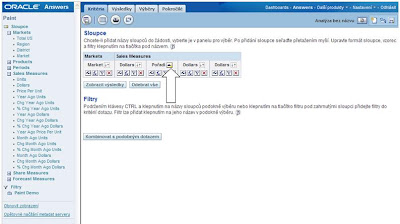
6. Poslední sloupec bude sloužit pro agregaci dle skupin „Nejlepších 5“, „Nejhorších 5“ a „Ostatní“. Klikněte opět na „Upravit sloupec“ a aplikujte následující vzorec:
CASE WHEN Rank("Sales Measures".Dollars) <= 5 THEN 'Nejlepších 5' WHEN Rank("Sales Measures".Dollars) > MAX(RANK("Sales Measures".Dollars))-5 THEN 'Nejhorších 5' ELSE 'Ostatní' END
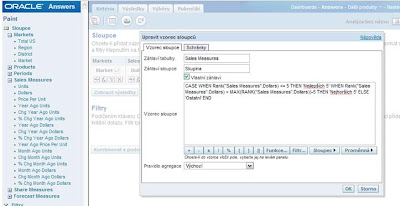
Takto nyní vypadá seznam sloupců ve výběru kritérií:

7. Nyní se přepněte do zobrazení kontingenční tabulky. Vylučte sloupce Pořadí a Market (původní dimenze). V části Míry ponechte pouze sloupec Dollars (faktová tabulka) a sloupec Skupina a Pobočky umístěte do sekce řádků:
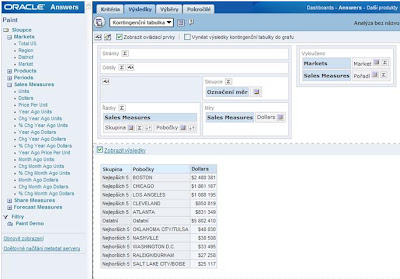
8. Sloupec skupina skryjte a nastavte pro něj součty (symbol ∑ - volba „za“). Také zvolte celkový součet v sekci řádky.
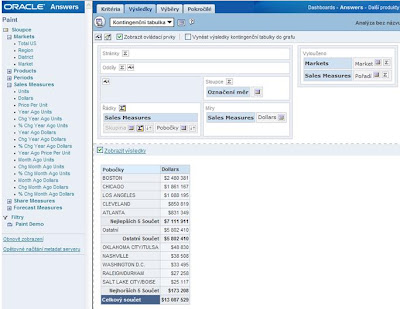
9. Graf pro takovéto společné výsledky nemá v podstatě smysl, neboť obvykle, jako i v tomto případě, jsou výsledky ze spodní části tabulky o několik řádů menší než ty z horní části. Pokud byste však chtěli graf použít, je možné výsledná data ještě filtrovat. Ukažme si možnost filtru pomocí výzvy sloupce:
a/ Na záložce „Výběry“ zvolte „Vytvořit výzvu – Výzva filtru sloupce“ a formulář vyplňte následovně (v prvním rozevíracím seznamu – Filtr podle sloupce - vyberte poslední hodnotu):
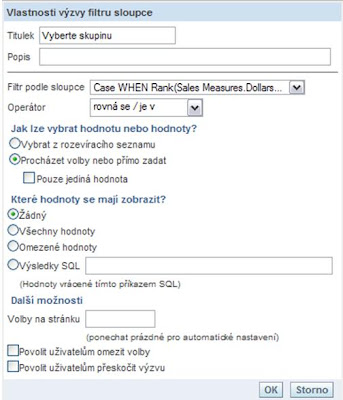
b/ Potvrďte OK. Test výzvy vypadá následovně (například):
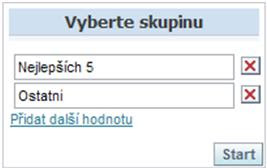
Hodnoty však nejdou nabídnout přímo, vzhledem k tomu, že jsou z vypočítaného sloupce. Musíte je tedy zadávat ručně. Pokud se překlepnete, žádná data nebudou vrácena.
c/ Výsledek pak vypadá takto:
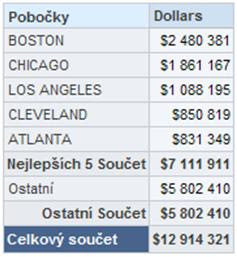
10. Přidejme tedy graf:
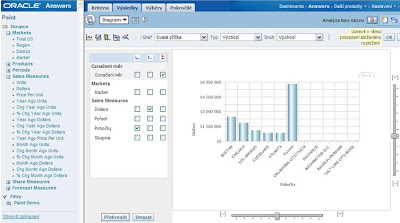
11. Graf zařaďte do složeného pohledu (Compound Layout) a otestujte sestavu prostřednictvím testovací výzvy:
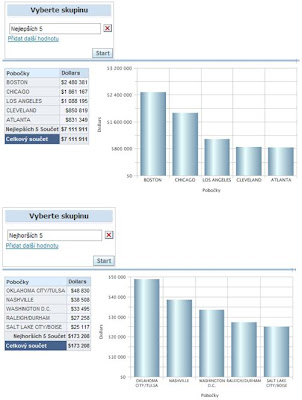
Mohli jste samozřejmě ještě použít dynamicky naplněnou hodnotu počtu nejlepších/nejhorších výsledků pomocí prezentační proměnné, jak je naznačeno v původním příkladu.
1. Vyberte Jeden sloupec s dimenzí a jeden faktový

2. Stejný faktový sloupec přidejte ještě 3x

3. Jeho druhý výskyt upravte (Upravit sloupec)

4. Na témže sloupci nastavte třídění

5. Následující sloupec bude sloužit pro určení toho, které z řádků patří mezi „Nejlepších 5“ a které mezi „Nejhorších 5“. Zvolte opět „Upravit sloupec“ (tlačítko fx) a použijte následující CASE příkaz:
CASE WHEN RANK("Sales Measures".Dollars) <= 5 THEN Markets.Market WHEN RANK("Sales Measures".Dollars) > MAX(RANK("Sales Measures".Dollars))-5 THEN Markets.Market ELSE 'Ostatní' END
V takto upraveném sloupci budou zobrazeny názvy poboček (hodnot dimenze) v případě, že jsou mezi prvními nebo posledními 5ti. V opačném případě bude v tomto sloupci hodnota „Ostatní“

6. Poslední sloupec bude sloužit pro agregaci dle skupin „Nejlepších 5“, „Nejhorších 5“ a „Ostatní“. Klikněte opět na „Upravit sloupec“ a aplikujte následující vzorec:
CASE WHEN Rank("Sales Measures".Dollars) <= 5 THEN 'Nejlepších 5' WHEN Rank("Sales Measures".Dollars) > MAX(RANK("Sales Measures".Dollars))-5 THEN 'Nejhorších 5' ELSE 'Ostatní' END

Takto nyní vypadá seznam sloupců ve výběru kritérií:

7. Nyní se přepněte do zobrazení kontingenční tabulky. Vylučte sloupce Pořadí a Market (původní dimenze). V části Míry ponechte pouze sloupec Dollars (faktová tabulka) a sloupec Skupina a Pobočky umístěte do sekce řádků:

8. Sloupec skupina skryjte a nastavte pro něj součty (symbol ∑ - volba „za“). Také zvolte celkový součet v sekci řádky.

9. Graf pro takovéto společné výsledky nemá v podstatě smysl, neboť obvykle, jako i v tomto případě, jsou výsledky ze spodní části tabulky o několik řádů menší než ty z horní části. Pokud byste však chtěli graf použít, je možné výsledná data ještě filtrovat. Ukažme si možnost filtru pomocí výzvy sloupce:
a/ Na záložce „Výběry“ zvolte „Vytvořit výzvu – Výzva filtru sloupce“ a formulář vyplňte následovně (v prvním rozevíracím seznamu – Filtr podle sloupce - vyberte poslední hodnotu):

b/ Potvrďte OK. Test výzvy vypadá následovně (například):

Hodnoty však nejdou nabídnout přímo, vzhledem k tomu, že jsou z vypočítaného sloupce. Musíte je tedy zadávat ručně. Pokud se překlepnete, žádná data nebudou vrácena.
c/ Výsledek pak vypadá takto:

10. Přidejme tedy graf:

11. Graf zařaďte do složeného pohledu (Compound Layout) a otestujte sestavu prostřednictvím testovací výzvy:

Mohli jste samozřejmě ještě použít dynamicky naplněnou hodnotu počtu nejlepších/nejhorších výsledků pomocí prezentační proměnné, jak je naznačeno v původním příkladu.
Petr Zeman (OKsystem)
čtvrtek 4. prosince 2008
ODI - Reverse-engineering stávajícího datového modelu
Dalším krokem po založení Projektu a naimportovaní Knowledge modulů je načtení zdrojových/cílových dat. modelů (tj. tabulek, pohledů, atd.), které budou zahrnuty do samotné integrace.
Podívejte se na video ukazující "step-by-step" postup jak v ODI provést reverse-engineering stávajícího datového modelu.
Příští díl bude o tom jak v ODI na základě zdrojového dat. modelu vytvořit model cílový (neboli jak migrovat datové modely mezi různými technologiemi).
Peter Hora (Semanta).
Podívejte se na video ukazující "step-by-step" postup
jak v ODI provést reverse-engineering stávajícího datového modelu.Příští díl bude o tom jak v ODI na základě zdrojového dat. modelu vytvořit model cílový (neboli jak migrovat datové modely mezi různými technologiemi).
Peter Hora (Semanta).
pondělí 1. prosince 2008
Chybějící BI Office Add-in – může se to stát i Vám
Nedávno jsem měl prezentaci, na které se měla ukazovat funkcionalita komponenty BI Office Add-in pro MS Excel a MS PowerPoint.
Před prezentací vždy kontroluji, že vše funguje .... a ejhle BI Office Add-in pro MS PowerPoint chybí! (ale BI Add-in pro MS Excel existoval a fungoval správně).
Co s tím? Rychle jsem celý BI Office Add-in reinstaloval ... Add-in pro Excel fungoval, ale Add-in pro PowerPoint stále chyběl. Rychle jsem celý BI Office Add-in odinstaloval ... restartoval PC .... nainstaloval .... restartoval PC ... výsledek BI Add-in pro Excel fungoval, ale BI Add-in pro PowerPoint stále chyběl :(
Prohledal jsem web a na nějakém MS fóru jsem našel, že MS Office v nějakých případech vypne integrované Add-ins.
Opětovně zapnout Add-in v MS Office můžete pomocí menu Help > About MS Office ... > Disabled Items ... > vyberete Add-in z menu > a zvolíte Enable.
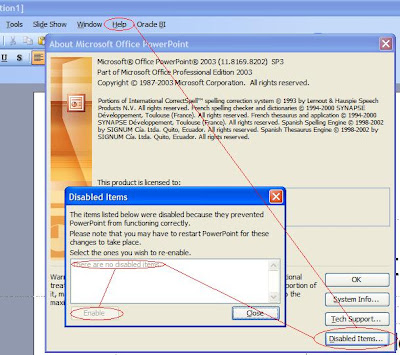
Před prezentací vždy kontroluji, že vše funguje .... a ejhle BI Office Add-in pro MS PowerPoint chybí! (ale BI Add-in pro MS Excel existoval a fungoval správně).
Co s tím? Rychle jsem celý BI Office Add-in reinstaloval ... Add-in pro Excel fungoval, ale Add-in pro PowerPoint stále chyběl. Rychle jsem celý BI Office Add-in odinstaloval ... restartoval PC .... nainstaloval .... restartoval PC ... výsledek BI Add-in pro Excel fungoval, ale BI Add-in pro PowerPoint stále chyběl :(
Prohledal jsem web a na nějakém MS fóru jsem našel, že MS Office v nějakých případech vypne integrované Add-ins.
Opětovně zapnout Add-in v MS Office můžete pomocí menu Help > About MS Office ... > Disabled Items ... > vyberete Add-in z menu > a zvolíte Enable.

Erik Eckhardt.
čtvrtek 27. listopadu 2008
ODI - Definice projektů a import KM
Poté co je nadefinovaná topologie můžete začít vytvářet první integrační projekty.
Podívejte se na video ukazující "step-by-step" postup jak v ODI vytvořit Projekt a naimportovat potřebné Knowledge Moduly (KM).
Příští díl bude o tom jak v ODI provést reverse-engineering stávajícího datového modelu.
Peter Hora (Semanta).
Podívejte se na video ukazující "step-by-step" postup
jak v ODI vytvořit Projekt a naimportovat potřebné Knowledge Moduly (KM).Příští díl bude o tom jak v ODI provést reverse-engineering stávajícího datového modelu.
Peter Hora (Semanta).
pondělí 24. listopadu 2008
Optimalizace dotazů s použitím HINTů
V tomto příspěvku bych se chtěl podělit o zkušenost s atributem Hint, který jsme byli nuceni použít z důvodu optimalizace dotazů.
Po implementaci dashboardu u jednoho nejmenovaného klienta doba trvání všech dotazů probíhala v požadovaných časech (1-3 sekundy). Cca 2 měsíce po nasazení do produkčního provozu došlo k náhlému poklesu výkonnosti dotazů až na několik desítek minut. Toto bylo způsobeno tím, že faktové tabulky se měsíčně „rozmnožovaly“ o cca 10 miliónů záznamů.
Optimalizaci jsme se rozhodli vyřešit nasazením atributů hint v metadatech přímo u fyzické tabulky. Po nasazení se výkon dotazů vrátil do původních požadovaných časových intervalů (u některých dotazů byla doba trvání dotazu dokonce nižší než po zahájení produkčního provozu).
Pro nastavení jednoho HINTu vše funguje jak má:
Např. syntaxe pro použití konkrétního indexu je: INDEX(název_tabulky, název_indexu) Hint se uvádí u tabulek ve Fyzické vrstvě metadata repository:
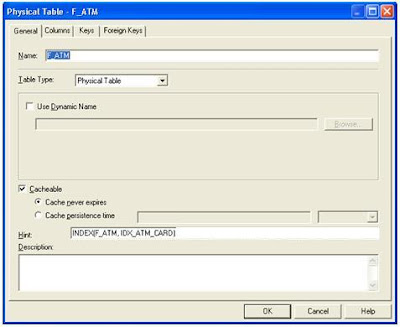
My jsme ale museli řešit požadavek, kdy u daného dotazu se mohly zadat různé filtry (podmínky) na více hlavních atributů – vždy alespoň na jeden z nich. Na každý daný hlavní atribut byl v databázi použit index na který jsme chtěli nastavit hint. Syntaxe použití více hintů najednou je (opět pro index) tato (oddělovačem je mezera):
INDEX(název_tabulky, název_indexu) INDEX(název_tabulky, název_indexu) INDEX(název_tabulky, název_indexu)
Bohužel použitá verze OBI EE (10.1.3.3.0) neumí tento zápis rozklíčovat.
Řešení je jednoduché („vypocené“): pro 2. a další hint se nesmí použít název fyzické tabulky, ale její alias, pod kterým je uvedena ve výsledném fyzickém SQL.
Naštěstí je tento alias neměnný (zřejmě se generuje z identifikátoru, pod kterým je tabulka uložená v metadatech).
Příklad:
INDEX(F_ATM, IDX_ATM_CARD) INDEX(T1391, IDX_ATM_TERM) INDEX(T1391, IDX_ATM_POSTDAT_AUDIT)
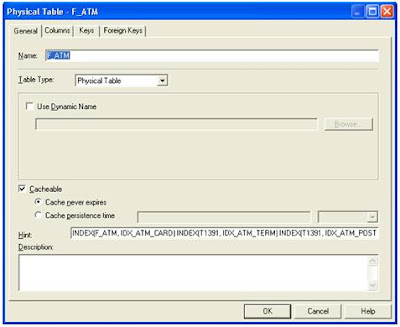
Miroslav Petr (konzultant společnosti Adastra).
Po implementaci dashboardu u jednoho nejmenovaného klienta doba trvání všech dotazů probíhala v požadovaných časech (1-3 sekundy). Cca 2 měsíce po nasazení do produkčního provozu došlo k náhlému poklesu výkonnosti dotazů až na několik desítek minut. Toto bylo způsobeno tím, že faktové tabulky se měsíčně „rozmnožovaly“ o cca 10 miliónů záznamů.
Optimalizaci jsme se rozhodli vyřešit nasazením atributů hint v metadatech přímo u fyzické tabulky. Po nasazení se výkon dotazů vrátil do původních požadovaných časových intervalů (u některých dotazů byla doba trvání dotazu dokonce nižší než po zahájení produkčního provozu).
Pro nastavení jednoho HINTu vše funguje jak má:
Např. syntaxe pro použití konkrétního indexu je: INDEX(název_tabulky, název_indexu) Hint se uvádí u tabulek ve Fyzické vrstvě metadata repository:

My jsme ale museli řešit požadavek, kdy u daného dotazu se mohly zadat různé filtry (podmínky) na více hlavních atributů – vždy alespoň na jeden z nich. Na každý daný hlavní atribut byl v databázi použit index na který jsme chtěli nastavit hint. Syntaxe použití více hintů najednou je (opět pro index) tato (oddělovačem je mezera):
INDEX(název_tabulky, název_indexu) INDEX(název_tabulky, název_indexu) INDEX(název_tabulky, název_indexu)
Bohužel použitá verze OBI EE (10.1.3.3.0) neumí tento zápis rozklíčovat.
Řešení je jednoduché („vypocené“): pro 2. a další hint se nesmí použít název fyzické tabulky, ale její alias, pod kterým je uvedena ve výsledném fyzickém SQL.
Naštěstí je tento alias neměnný (zřejmě se generuje z identifikátoru, pod kterým je tabulka uložená v metadatech).
Příklad:
INDEX(F_ATM, IDX_ATM_CARD) INDEX(T1391, IDX_ATM_TERM) INDEX(T1391, IDX_ATM_POSTDAT_AUDIT)

Miroslav Petr (konzultant společnosti Adastra).
středa 19. listopadu 2008
ODI a Topologie
Co je ODI, jak funguje a jaké jsou jeho výhody najdete zde. Kde najít instalační média a jak se instaluje najde zde.
Než v ODI začnete vytvářet samotné datové integrace, tak nejprve musíte zadefinovat „Topology“ – tj. umístění všech zdrojových a cílových systému, které se v ODI budou používat.
V rámci Topologie je potřeba zadefinovat:
Podívejte se na video ukazující "step-by-step" postup jak v ODI nadefinovat:
Příští díl bude o tom jak v ODI definovat projekty.
Erik Eckhardt a Peter Hora (Semanta).
Než v ODI začnete vytvářet samotné datové integrace, tak nejprve musíte zadefinovat „Topology“ – tj. umístění všech zdrojových a cílových systému, které se v ODI budou používat.
V rámci Topologie je potřeba zadefinovat:
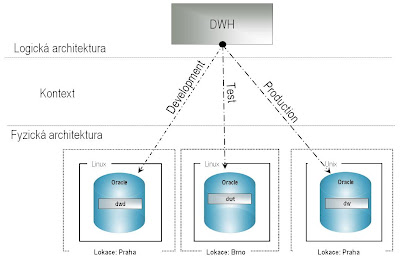
- Fyzickou architekturu – fyzické umístění datových zdrojů (včetně schémat) pro jednotlivé technologie, např.:
PHY_Arch_D = Tech: Oracle, Host: Praha, Instance: BIDWD, Schema: DWD
PHY_Arch_T = Tech: Oracle, Host: Brno, Instance: BIDWT, Schema: DWT
PHY_Arch_P = Tech: Oracle, Host: Praha, Instance: BIDW, Schema: DW - Logickou architekturu – alias pro rozdílné fyzické zdroje dat, které mají stejnou datovou strukturu, jsou založené na stejné technologii, ale vystupují v různých kontextech, např.:
DWH - Kontext – “situace”, ve které se mapuje logická architektura na fyzickou architekturu, např.:
Kontext DEVELOPMENT = DWH <-> PHY_Arch_D
Kontext TEST = DWH <-> PHY_Arch_T
Kontext PRODUCTION = DWH <-> PHY_Arch_P

Podívejte se na video ukazující "step-by-step" postup jak v ODI nadefinovat:
Příští díl bude o tom jak v ODI definovat projekty.
Erik Eckhardt a Peter Hora (Semanta).
čtvrtek 13. listopadu 2008
Jak s pomocí BI Delivers ukládat sestavy BI Answers do souborů
Článek popisuje postup jak s pomocí komponenty BI Delivers lze generovat reporty vytvořené v BI Answers přímo do souborů na filesystému. Podmínkou fungování je zprovoznění služby Oracle BI Scheduler - postup najdete zde.
1. NASTAVENÍ SLUŽBY JAVAHOST PRO ODESÍLÁNÍ IBOTŮ DO VLASTNÍCH JAVA TŘÍD
Konfigurační soubor služby JavaHost je na cestě [OracleBI]\web\javahost\config\config.xml. V tomto souboru je třeba nastavit v tagu "Scheduler" hodnotu "Enabled" na „True“ a přidat nebo odkomentovat tag "DefaultUserJarFilePath". Celý tag pak vypadá takto:
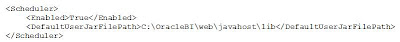
Dále je nutné zvýšit výchozí hodnoty pro PDF a InputStream (změňte nebo přidejte kamkoliv do config.xml):

Uložte soubor a přestartujte službu Oracle BI Java Host.
2. VLASTNÍ JAVA TŘÍDA PRO UKLÁDÁNÍ REPORTŮ DO SOUBORU
Pro vytvoření jednoduchého programu pro ukládání reportů do souboru jsem použil DeliveryManager API, které je součástí Oracle BI Publisheru a Scheduler API. Tato API jsou obsažená ve třech souborech *.jar, které je třeba přibalit do vlastního *.jar souboru s programem. Jsou to následující: xdocore.jar, versioninfo.jar a schedulerrpccalls.jar.
Vytvořený soubor jsem pojmenoval okdeliver.jar. Abyste mohli vlastní třídu používat, umístěte soubor okdeliver.jar na BI server na cestu, kterou jste nastavili v předchozím kroku jako DefaultUserJarFilePath. Třída samotná je nazvaná cz.oksystem.mis.delivery.Deliver. Tento plný název je třeba uvádět v místě jejího použití (viz níže). Zdrojový kód třídy je uveden na konci článku.
3. PRESENTATION SERVICES A OPRÁVNĚNÍ PRO PRÁCI S DELIVERY
Po instalaci Oracle BI nemá v Presentation Services nikdo oprávnění pro práci s iBoty a Delivery. To je třeba přidat. Přihlaste se proto jako uživatel ze skupiny Administrators – například Administrator k webovému rozhraní Presentation Services a zvolte Nastavení – Správa v pravé horní části okna. Otevře se okno pro administraci Prezentation Services:
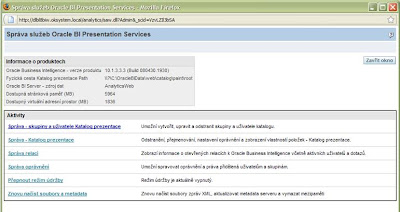
Zde zvolte první odkaz –Správa – skupiny a uživatele Katalog prezentace. Zvolte Upravit u skupiny Presentation Server Administrators, dále pak Přidat nového člena – Zobrazit uživatele a skupiny a nakonec klikněte na Přidat u uživatele SchedulerAdmin.
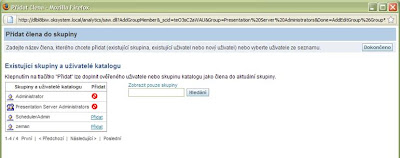
Dvakrát potvrďte operaci tlačítkem Dokončeno. Pokračujte kliknutím na odkaz Správa oprávnění a dále srolujte k části s oprávněními pro Delivers:
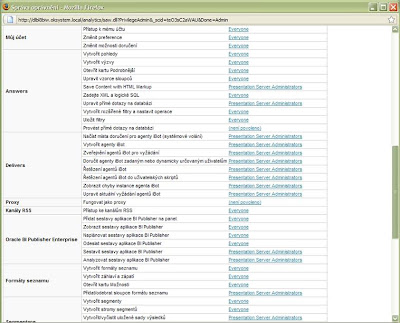
Klikněte na odkaz „není povoleno“ na každém řádku v části Delivers a přidejte oprávnění pro skupinu Presentation Server Administrators. Akci potvrďte tlačítkem Dokončeno. Jakmile budete mít přidělena oprávnění tak, jak je vidět na obrázku výše, potvrďte celou akci tlačítkem Dokončeno v horní části okna a nakonec klikněte na tlačítko Zavřít okno.
DŮLEŽITÁ POZNÁMKA: Pokud autentizace BI je nastavena proti externímu zdroji, nesmí být uživatel, který vytváří a spouští iBoty současně v metadata repository. Pokud se tak stane, nebude probíhat spouštění iBotů (chyba: [nQSError: 10018] Access for the requested connection is refused. [nQSError: 13024] Successful completion of init block 'AUTH_IB' is required.).
V testovacím prostředí byl založen uživatel iBoter pouze v LDAP, zařazený do skupiny Administrators. Pod tímto uživatelem je třeba se jednou přihlásit a odhlásit, aby vznikl jeho záznam v Presentation Services katalogu. Poté se přihlašte jako Administrator a přidejte ho do skupiny Presentation Server Administrators jak je popsáno výše. Všechny další kroky při vytváření a správě iBotů provádějte jako uživatel iBoter. Uživatel SchedulerAdmin, který je superuživatelem pro službu Oracle BI Scheduler musí být zařazený v Presentation Server Administrators v každém případě! (jinak nastane při provádění iBotu chyba: [nQSError: 77006] Oracle BI Presentation Server Error: Access denied.).
4. VYTVOŘENÍ IBOTU A NASTAVENÍ JEHO DORUČENÍ DO VLASTNÍ TŘÍDY
Ve webovém rozhraní Presentation Services zvolte Další produkty – Delivers. Dále klikněte na odkaz Vytvořit nového agenta iBot. Na následujícím obrázku je vidět okno se záložkami pro vytváření a konfiguraci iBotů:
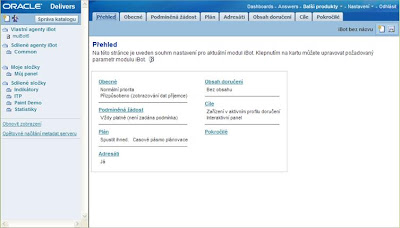
První záložka, kterou budete měnit (pokud je třeba) je Plán (konfigurace pro Scheduler). Zde je nastaveno jako výchozí jednorázové okamžité vykonání iBota. Nastavte plán podle vlastních požadavků. Dále na záložce Adresáti ponechte označeno „Já“ (musí být alespoň jeden adresát iBota, jinak iBot nevrátí žádná data). Na záložce Obsah doručení vyberte sestavu, která má být iBotem vykonávána (tlačítko Vybrat obsah...) a potom zvolte v roletě „Odeslat obsah jako“ příslušný formát (např. Příloha (PDF)). Otestované jako funkční jsou formáty PDF, CSV, XLS (Excel i Excel 2000). Na záložce Cíle odznačte všechna zaškrtnutá pole a zaškrtněte pouze Oracle BI Server Mezipaměť v sekci Systémové služby.
Nejdůležitější část konfigurace iBotu provedete na záložce Pokročilé. Klikněte na první tlačítko Přidat akci a z nabídky zvolte „vlastní program Java“ . Do pole Název třídy vyplňte cz.oksystem.mis.delivery.Deliver. Do pole Cesta třídy napište okdeliver.jar. Přepněte radibuton Výsledky na hodnotu „Předat programu Java obsah doručení“ a přidejte dva Jiné parametry. První uvádí cestu souboru včetně jeho názvu bez koncovky a druhý uvádí koncovku (typ) souboru. Koncovka musí odpovídat zvolenému formátu odesílaného obsahu (viz Odeslat obsah jako na záložce Obsah doručení). Na obrázku níže si všimněte především dvojitých zpětných lomítek v uváděné cestě:
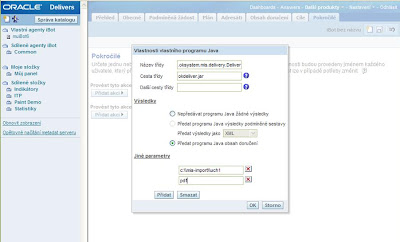
Třída Deliver přidá k názvu souboru ještě časové razítko ve formátu _rrrr-MM-dd-hh-mm-ss a soubor uloží v příslušném formátu na uvedenou cestu (adresáře v cestě musejí existovat).
Zdrojový kód třídy cz.oksystem.mis.delivery.Deliver
package cz.oksystem.mis.delivery;
import com.siebel.analytics.scheduler.javahostrpccalls.SchedulerJavaExtension;
import com.siebel.analytics.scheduler.javahostrpccalls.SchedulerJobException;
import com.siebel.analytics.scheduler.javahostrpccalls.SchedulerJobInfo;
import java.io.FileInputStream;
import java.sql.Timestamp;
import java.util.Date;
import java.util.StringTokenizer;
import oracle.apps.xdo.delivery.DeliveryManager;
import oracle.apps.xdo.delivery.DeliveryRequest;
import oracle.apps.xdo.delivery.local.LocalPropertyDefinitions;
public class Deliver implements SchedulerJavaExtension{
public Deliver() {
}
public void run(SchedulerJobInfo jobInfo) throws SchedulerJobException {
try {
String filename = "c:\\mis-import\\sestava";
String extense = "pdf";
if (jobInfo.parameterCount() > 0) {
filename = jobInfo.parameter(0);
extense = jobInfo.parameter(1);
}
Date dnes = new Date();
Timestamp timestamp = new Timestamp(dnes.getTime());
String razitko = timestamp.toString();
razitko = replaceAllWords(razitko," ", "-");
razitko = replaceAllWords(razitko,":", "-");
razitko = razitko.substring(0,razitko.length()-4);
String cesta = filename + "_" + razitko + "." + extense;
FileInputStream fileInputStr = new FileInputStream(jobInfo.getResultSetFile());
DeliveryManager delMan = new DeliveryManager();
DeliveryRequest delReq = delMan.createRequest(DeliveryManager.TYPE_LOCAL);
delReq.addProperty(LocalPropertyDefinitions.LOCAL_DESTINATION, cesta);
delReq.setDocument(fileInputStr);
delReq.submit();
delReq.close();
}
catch(Exception ex) {
throw new SchedulerJobException(1, 1, ex.getMessage());
}
}
public void cancel() {
}
private String replaceAllWords(String original, String find, String replacement) {
StringBuilder result = new StringBuilder(original.length());
String delimiters = "$+-*/(),.: ";
StringTokenizer st = new StringTokenizer(original, delimiters, true);
String navrat = null;
while (st.hasMoreTokens()) {
String w = st.nextToken();
if (w.equals(find)) {
result.append(replacement);
} else {
result.append(w);
}
}
navrat = result.toString();
return navrat;
}
}
1. NASTAVENÍ SLUŽBY JAVAHOST PRO ODESÍLÁNÍ IBOTŮ DO VLASTNÍCH JAVA TŘÍD
Konfigurační soubor služby JavaHost je na cestě [OracleBI]\web\javahost\config\config.xml. V tomto souboru je třeba nastavit v tagu "Scheduler" hodnotu "Enabled" na „True“ a přidat nebo odkomentovat tag "DefaultUserJarFilePath". Celý tag pak vypadá takto:

Dále je nutné zvýšit výchozí hodnoty pro PDF a InputStream (změňte nebo přidejte kamkoliv do config.xml):

Uložte soubor a přestartujte službu Oracle BI Java Host.
2. VLASTNÍ JAVA TŘÍDA PRO UKLÁDÁNÍ REPORTŮ DO SOUBORU
Pro vytvoření jednoduchého programu pro ukládání reportů do souboru jsem použil DeliveryManager API, které je součástí Oracle BI Publisheru a Scheduler API. Tato API jsou obsažená ve třech souborech *.jar, které je třeba přibalit do vlastního *.jar souboru s programem. Jsou to následující: xdocore.jar, versioninfo.jar a schedulerrpccalls.jar.
Vytvořený soubor jsem pojmenoval okdeliver.jar. Abyste mohli vlastní třídu používat, umístěte soubor okdeliver.jar na BI server na cestu, kterou jste nastavili v předchozím kroku jako DefaultUserJarFilePath. Třída samotná je nazvaná cz.oksystem.mis.delivery.Deliver. Tento plný název je třeba uvádět v místě jejího použití (viz níže). Zdrojový kód třídy je uveden na konci článku.
3. PRESENTATION SERVICES A OPRÁVNĚNÍ PRO PRÁCI S DELIVERY
Po instalaci Oracle BI nemá v Presentation Services nikdo oprávnění pro práci s iBoty a Delivery. To je třeba přidat. Přihlaste se proto jako uživatel ze skupiny Administrators – například Administrator k webovému rozhraní Presentation Services a zvolte Nastavení – Správa v pravé horní části okna. Otevře se okno pro administraci Prezentation Services:

Zde zvolte první odkaz –Správa – skupiny a uživatele Katalog prezentace. Zvolte Upravit u skupiny Presentation Server Administrators, dále pak Přidat nového člena – Zobrazit uživatele a skupiny a nakonec klikněte na Přidat u uživatele SchedulerAdmin.

Dvakrát potvrďte operaci tlačítkem Dokončeno. Pokračujte kliknutím na odkaz Správa oprávnění a dále srolujte k části s oprávněními pro Delivers:

Klikněte na odkaz „není povoleno“ na každém řádku v části Delivers a přidejte oprávnění pro skupinu Presentation Server Administrators. Akci potvrďte tlačítkem Dokončeno. Jakmile budete mít přidělena oprávnění tak, jak je vidět na obrázku výše, potvrďte celou akci tlačítkem Dokončeno v horní části okna a nakonec klikněte na tlačítko Zavřít okno.
DŮLEŽITÁ POZNÁMKA: Pokud autentizace BI je nastavena proti externímu zdroji, nesmí být uživatel, který vytváří a spouští iBoty současně v metadata repository. Pokud se tak stane, nebude probíhat spouštění iBotů (chyba: [nQSError: 10018] Access for the requested connection is refused. [nQSError: 13024] Successful completion of init block 'AUTH_IB' is required.).
V testovacím prostředí byl založen uživatel iBoter pouze v LDAP, zařazený do skupiny Administrators. Pod tímto uživatelem je třeba se jednou přihlásit a odhlásit, aby vznikl jeho záznam v Presentation Services katalogu. Poté se přihlašte jako Administrator a přidejte ho do skupiny Presentation Server Administrators jak je popsáno výše. Všechny další kroky při vytváření a správě iBotů provádějte jako uživatel iBoter. Uživatel SchedulerAdmin, který je superuživatelem pro službu Oracle BI Scheduler musí být zařazený v Presentation Server Administrators v každém případě! (jinak nastane při provádění iBotu chyba: [nQSError: 77006] Oracle BI Presentation Server Error: Access denied.).
4. VYTVOŘENÍ IBOTU A NASTAVENÍ JEHO DORUČENÍ DO VLASTNÍ TŘÍDY
Ve webovém rozhraní Presentation Services zvolte Další produkty – Delivers. Dále klikněte na odkaz Vytvořit nového agenta iBot. Na následujícím obrázku je vidět okno se záložkami pro vytváření a konfiguraci iBotů:

První záložka, kterou budete měnit (pokud je třeba) je Plán (konfigurace pro Scheduler). Zde je nastaveno jako výchozí jednorázové okamžité vykonání iBota. Nastavte plán podle vlastních požadavků. Dále na záložce Adresáti ponechte označeno „Já“ (musí být alespoň jeden adresát iBota, jinak iBot nevrátí žádná data). Na záložce Obsah doručení vyberte sestavu, která má být iBotem vykonávána (tlačítko Vybrat obsah...) a potom zvolte v roletě „Odeslat obsah jako“ příslušný formát (např. Příloha (PDF)). Otestované jako funkční jsou formáty PDF, CSV, XLS (Excel i Excel 2000). Na záložce Cíle odznačte všechna zaškrtnutá pole a zaškrtněte pouze Oracle BI Server Mezipaměť v sekci Systémové služby.
Nejdůležitější část konfigurace iBotu provedete na záložce Pokročilé. Klikněte na první tlačítko Přidat akci a z nabídky zvolte „vlastní program Java“ . Do pole Název třídy vyplňte cz.oksystem.mis.delivery.Deliver. Do pole Cesta třídy napište okdeliver.jar. Přepněte radibuton Výsledky na hodnotu „Předat programu Java obsah doručení“ a přidejte dva Jiné parametry. První uvádí cestu souboru včetně jeho názvu bez koncovky a druhý uvádí koncovku (typ) souboru. Koncovka musí odpovídat zvolenému formátu odesílaného obsahu (viz Odeslat obsah jako na záložce Obsah doručení). Na obrázku níže si všimněte především dvojitých zpětných lomítek v uváděné cestě:

Třída Deliver přidá k názvu souboru ještě časové razítko ve formátu _rrrr-MM-dd-hh-mm-ss a soubor uloží v příslušném formátu na uvedenou cestu (adresáře v cestě musejí existovat).
Zdrojový kód třídy cz.oksystem.mis.delivery.Deliver
package cz.oksystem.mis.delivery;
import com.siebel.analytics.scheduler.javahostrpccalls.SchedulerJavaExtension;
import com.siebel.analytics.scheduler.javahostrpccalls.SchedulerJobException;
import com.siebel.analytics.scheduler.javahostrpccalls.SchedulerJobInfo;
import java.io.FileInputStream;
import java.sql.Timestamp;
import java.util.Date;
import java.util.StringTokenizer;
import oracle.apps.xdo.delivery.DeliveryManager;
import oracle.apps.xdo.delivery.DeliveryRequest;
import oracle.apps.xdo.delivery.local.LocalPropertyDefinitions;
public class Deliver implements SchedulerJavaExtension{
public Deliver() {
}
public void run(SchedulerJobInfo jobInfo) throws SchedulerJobException {
try {
String filename = "c:\\mis-import\\sestava";
String extense = "pdf";
if (jobInfo.parameterCount() > 0) {
filename = jobInfo.parameter(0);
extense = jobInfo.parameter(1);
}
Date dnes = new Date();
Timestamp timestamp = new Timestamp(dnes.getTime());
String razitko = timestamp.toString();
razitko = replaceAllWords(razitko," ", "-");
razitko = replaceAllWords(razitko,":", "-");
razitko = razitko.substring(0,razitko.length()-4);
String cesta = filename + "_" + razitko + "." + extense;
FileInputStream fileInputStr = new FileInputStream(jobInfo.getResultSetFile());
DeliveryManager delMan = new DeliveryManager();
DeliveryRequest delReq = delMan.createRequest(DeliveryManager.TYPE_LOCAL);
delReq.addProperty(LocalPropertyDefinitions.LOCAL_DESTINATION, cesta);
delReq.setDocument(fileInputStr);
delReq.submit();
delReq.close();
}
catch(Exception ex) {
throw new SchedulerJobException(1, 1, ex.getMessage());
}
}
public void cancel() {
}
private String replaceAllWords(String original, String find, String replacement) {
StringBuilder result = new StringBuilder(original.length());
String delimiters = "$+-*/(),.: ";
StringTokenizer st = new StringTokenizer(original, delimiters, true);
String navrat = null;
while (st.hasMoreTokens()) {
String w = st.nextToken();
if (w.equals(find)) {
result.append(replacement);
} else {
result.append(w);
}
}
navrat = result.toString();
return navrat;
}
}
Petr Zeman (konzultant společnosti OKsystem).
pondělí 10. listopadu 2008

pondělí 3. listopadu 2008
2. Oracle Czech BI/DW Experts Bootcamp
V pátek 31.10.2008 proběhl 2. Oracle Czech BI/DW Experts Bootcamp, kterého se zúčastnilo 18 vybraných konzultantů od 13 Oracle partnerů:
Agenda setkání byla následující:
09:30 Zahájení a představení
09:40 Předání cen
09:45 Novinky – Oracle Exadata
10:00 1. workshop – Tipy, triky a zkušenosti z projektů
12:00 Oběd
13:15 1. workshop – Tipy, triky a zkušenosti z projektů (pokračování)
15:15 Novinky – Oracle Essbase
15:30 2. workshop – Co jsem v dokumentaci nenašel
17:30 Novinky – Oracle BI 10.1.3.4.0
17:45 Metalink3
18:00 Večeře, volná diskuse a zábava ...
Prezentace z 1. workshopu – Tipy, triky a zkušenosti z projektů:
13 prezentujících, 28 příspěvků:
Jan Gottinger (CCA)
Petr Zeman (OK System)
Václav Bíba (Ness | Logos)
Radovan Man (K2)
Jakub Genža (Sophias)
Jiří Bohuslav (Sophias)
Miroslav Petr (Adastra)
Jiří Doubravský (PIKE)
Michal Tomek (NEIT)
Michal Kocman (O2 Services)
Petr Jurášek (IT Systems)
Peter Hora (Semanta)
Michal Zima (Teura)
- Jaroslav Vlček (Adastra)
- Miroslav Petr (Adastra)
- Jan Gottinger (CCA)
- Jan Pospíšil (CD Telematika)
- Petr Jurászek (IT SYSTEMS)
- Radovan Man (K2 atmitec)
- David Glivický (K2 atmitec)
- Václav Bíba (NESS|Logos)
- Jindřich Štěpánek (OK system)
- Petr Zeman (OK system)
- Jiří Doubravský (Pike Electronics)
- Michal Tomek (Neit Consulting)
- Lukáš Hrnčíř (Neit Consulting)
- Jiří Bohuslav (Sophias)
- Jakub Genža (Sophias)
- Michal Kocman (Telefónica O2 Services)
- Michal Zima (Teura)
- Peter Hora (Semanta)
Agenda setkání byla následující:
09:30 Zahájení a představení
09:40 Předání cen
09:45 Novinky – Oracle Exadata
10:00 1. workshop – Tipy, triky a zkušenosti z projektů
12:00 Oběd
13:15 1. workshop – Tipy, triky a zkušenosti z projektů (pokračování)
15:15 Novinky – Oracle Essbase
15:30 2. workshop – Co jsem v dokumentaci nenašel
17:30 Novinky – Oracle BI 10.1.3.4.0
17:45 Metalink3
18:00 Večeře, volná diskuse a zábava ...
Prezentace z 1. workshopu – Tipy, triky a zkušenosti z projektů:
13 prezentujících, 28 příspěvků:
Jan Gottinger (CCA)
- Autentizace pomocí SSO
- Distribuce změn k zákazníkům
- Spojení 2 tabulek (union)
- Instalace OBI do prostředí VMware
Petr Zeman (OK System)
- BI Delivers a generování reportů do file systemu
- BI Publisher a integrace s BI Serverem a LDAPem
- Latin2 a ODBC na Linux/Unix platformě
Václav Bíba (Ness | Logos)
- „Nedimenzionální“ reporting v OBIEE
- Problém kumulací v pivot tabulce
- Informace o počtu záznamů sestavy
Radovan Man (K2)
- Integrace Oracle BI do IS K2 (Komunikace s OBI pomocí webové služby a GO URL)
- HTML stránky získané pomocí WS a GO URL obsahují v cestách k javascriptům a kaskádovým stylům předponu „Missing_“
Jakub Genža (Sophias)
- Použití writebacku pro stanovení hranic tachometru + zjištění omezení
- Možnost uživatelské změny svého hesla na strance „My Account“ včetně grafické úpravy
- Nastavení Delivery profilu (především email adresy) pomocí SA SYSTEM Subject Area pro použití v BI Delivers
Jiří Bohuslav (Sophias)
- Problémy s registrací a odregistrací lokací v OWB (uložení registračních údajů, nechtěná ztráta runtime history)
Miroslav Petr (Adastra)
- Zkušenosti s vytvářením, používaním a výkonností vlastních ukazatelů
- Optimalizace dotazů v OBI s použitím hints
Jiří Doubravský (PIKE)
- Použití zobrazení “výběr sloupce“ pro výběr hodnoty hierarchie
Michal Tomek (NEIT)
- Downgrade repository např. 10.1.3.3.2 -> 10.1.3.3.1
Michal Kocman (O2 Services)
- Nevyrovnaná stromová struktura dimenze, hierachie s rozdílnými listovými úrovněmi
- Přechod od Expressu bez AWM, velký objem AW => rozdělení, výpočty
Petr Jurášek (IT Systems)
- Zvláštní nápočty penetrací
Peter Hora (Semanta)
- Embedded video v reporte
- Simulacia výstupu waterfall chart
- Ergonomie reportov
Michal Zima (Teura)
- Jak nejlépe přistupovat k vývoji, testování a produkci u metadata repository
- Jak nejlépe přistupovat k vývoji, testování a produkci u web katalogu
čtvrtek 30. října 2008
Extrémní výkon pro Váš Datový sklad

pondělí 27. října 2008
Dva způsoby jak definovat vlastní výpočty (ukazatele) v Business modelu
Jak již bylo uvedeno v článku Oracle BI Metadata repository – IV. Tvorba vlastních ukazatelů, existují dva způsoby jak definovat vlastní výpočty (ukazatele), a to:
Není jedno, který z výše uvedených způsobů použijete. Pro každý z nich je generován jiný fyzický SQL dotaz, a to v určitých případech (viz. níže) může mít vliv na správnost / nesprávnost výsledků a dokonce i na výkon samotného dotazu:

Příklad, kdy je nutné použít výpočet na základě fyzických sloupců:
Pro správný výpočet celkových tržeb se pro každý řádek nejprve vynásobí cena za kus (Unit Price) počtem prodaných kusů (Units Sold) a poté se teprve aplikuje agregační funkce SUM().
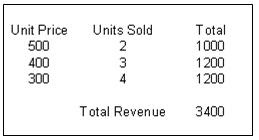
V případě použití výpočtu na základě již existujících logických sloupců, by byl výpočet celkových tržeb chybný. A to proto, že se nejprve aplikují agregační funkce SUM()
„Unit price“ je 500 + 400 + 300 = 1.200
„Units sold“ je 2 + 3 + 4 = 9
a až poté se provede vlastní výpočet, který je v tomto případě chybný: 1.200 x 9 = 10.800
Jak nadefinovat výpočet na základě fyzických sloupců
1. Vyberte faktovou tabulku > pravé tlačítko myši > New Object > Logical Column ...
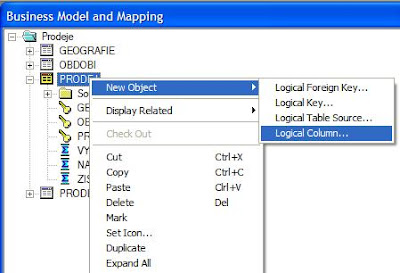
2. Pojmenujte ukazatel a zvolte OK.
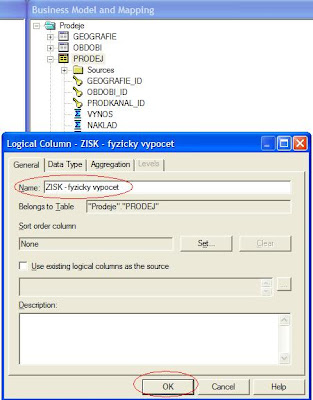
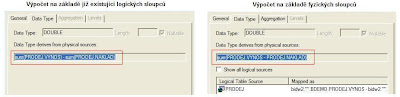
3. Vyberte fyzický zdroj Vaší logické tabulky a zvolte „Properties...“
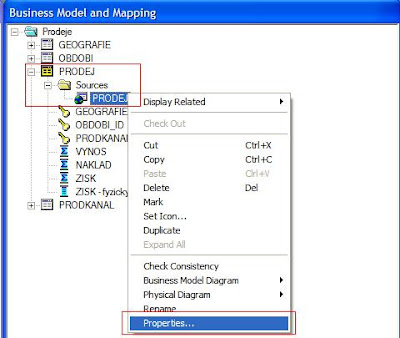
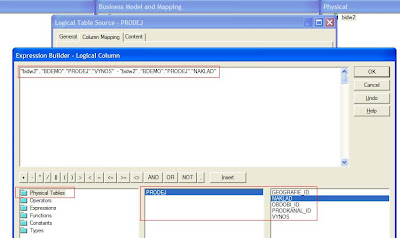
4. Vyberte záložku Column Mapping (zde je vidět, jak jsou mapovány jednotlivé logické sloupce z Business Modelu na Fyzickou vrstvu) > vyberte Váš nový ukazatel a spusťte Expression Builder (stiskněte ...)
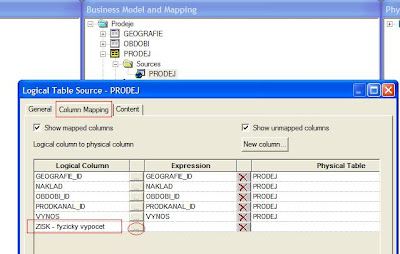
5. V Expression Builderu nadefinujte vlastní výpočet nad fyzickými sloupci a zvolte OK
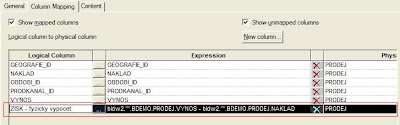
6. Výpočet je zobrazen v mapování mezi Business Modelem a Fyzickou vrstvou
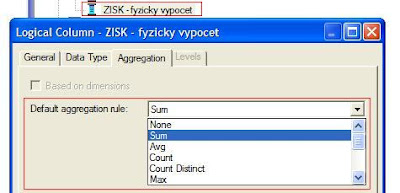
7. Nakonec nastavte agregační funkci pro Váš nový ukazatel a přesuňte jej do Prezentační vrstvy
Erik Eckhardt.
- Výpočet na základě již existujících logických sloupců (postup viz. článek výše)
- Výpočet na základě fyzických sloupců (postup je uveden níže)
Není jedno, který z výše uvedených způsobů použijete. Pro každý z nich je generován jiný fyzický SQL dotaz, a to v určitých případech (viz. níže) může mít vliv na správnost / nesprávnost výsledků a dokonce i na výkon samotného dotazu:
- U výpočtů na základě již existujících logických sloupců se nejprve aplikují agregační funkce (ty, které jsou nastaveny u logických sloupců ze kterých se vychází) a až poté se provede samotný výpočet
- U výpočtů na základě fyzických sloupců se nejprve provede výpočet a až poté se aplikuje agregační funkce


Příklad, kdy je nutné použít výpočet na základě fyzických sloupců:
Pro správný výpočet celkových tržeb se pro každý řádek nejprve vynásobí cena za kus (Unit Price) počtem prodaných kusů (Units Sold) a poté se teprve aplikuje agregační funkce SUM().

V případě použití výpočtu na základě již existujících logických sloupců, by byl výpočet celkových tržeb chybný. A to proto, že se nejprve aplikují agregační funkce SUM()
„Unit price“ je 500 + 400 + 300 = 1.200
„Units sold“ je 2 + 3 + 4 = 9
a až poté se provede vlastní výpočet, který je v tomto případě chybný: 1.200 x 9 = 10.800
Jak nadefinovat výpočet na základě fyzických sloupců
1. Vyberte faktovou tabulku > pravé tlačítko myši > New Object > Logical Column ...

2. Pojmenujte ukazatel a zvolte OK.

3. Vyberte fyzický zdroj Vaší logické tabulky a zvolte „Properties...“

4. Vyberte záložku Column Mapping (zde je vidět, jak jsou mapovány jednotlivé logické sloupce z Business Modelu na Fyzickou vrstvu) > vyberte Váš nový ukazatel a spusťte Expression Builder (stiskněte ...)

5. V Expression Builderu nadefinujte vlastní výpočet nad fyzickými sloupci a zvolte OK

6. Výpočet je zobrazen v mapování mezi Business Modelem a Fyzickou vrstvou

7. Nakonec nastavte agregační funkci pro Váš nový ukazatel a přesuňte jej do Prezentační vrstvy

Erik Eckhardt.
čtvrtek 23. října 2008
BI Publisher – Query Builder – doplnění chybějících agregačních funkcí
Jestliže pro vytváření SQL dotazů v BI Publisheru používáte Query Builder, pak jste si možná všimli, že v záložce „Podmínky - Funkce“ chybí agregační funkce pro číselné datové typy.
BI Publisher v pořádku rozezná datové typy sloupců z vybrané tabulky:
 ale pak pro jednotlivé datové typy vždy nabízí stejný seznam SQL funkcí – tj. funkcí, které jsou vhodné pro datový typ obsahují text.
ale pak pro jednotlivé datové typy vždy nabízí stejný seznam SQL funkcí – tj. funkcí, které jsou vhodné pro datový typ obsahují text.
 Seznam dostupných SQL funkcí pro jednotlivé datové typy je ve zdrojovém kódu BI Publisheru uveden správně, viz. funkce qb_rend[DATATYPE]Select().
Seznam dostupných SQL funkcí pro jednotlivé datové typy je ve zdrojovém kódu BI Publisheru uveden správně, viz. funkce qb_rend[DATATYPE]Select().
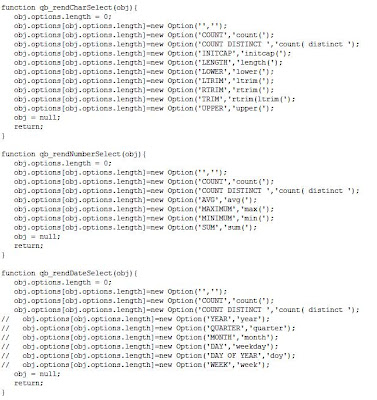
Bohužel z nějakého důvodu (nezkoumal jsem jej) dojde k chybnému zvolení datového typu a vždy je volána funkce qb_rendCharSelect, která generuje SQL funkce pro text.

Workaround
Upozornění: jde pouze o workaround a nasazením nové verze může být vše jinak!
1/ V adresáři J2EE serveru (server ve kterém běží aplikace BI Publisheru) najděte soubor „qb_gensql.js“ (např. D:\ OracleBI\oc4j_bi\j2ee\home\applications\xmlpserver\xmlpserver\qb\qbfiles\qb_gensql.js)
2/ Soubor zazálohujte
3/ Soubor otevřete a najděte v něm funkci qb_rendCharSelect
4/ Doplňte agregační funkce (řádky zkopírujte z funkce qb_rendNumberSelect)
 5/ Soubor uložte
5/ Soubor uložte
6/ Promažte lokální cache internetového prohlížeče a obnovte stránku Query Builderu – výsledkem je doplněný seznam SQL funkcí o funkce agregační
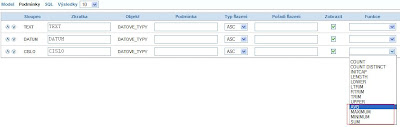
Erik Eckhardt.
BI Publisher v pořádku rozezná datové typy sloupců z vybrané tabulky:
 ale pak pro jednotlivé datové typy vždy nabízí stejný seznam SQL funkcí – tj. funkcí, které jsou vhodné pro datový typ obsahují text.
ale pak pro jednotlivé datové typy vždy nabízí stejný seznam SQL funkcí – tj. funkcí, které jsou vhodné pro datový typ obsahují text. Seznam dostupných SQL funkcí pro jednotlivé datové typy je ve zdrojovém kódu BI Publisheru uveden správně, viz. funkce qb_rend[DATATYPE]Select().
Seznam dostupných SQL funkcí pro jednotlivé datové typy je ve zdrojovém kódu BI Publisheru uveden správně, viz. funkce qb_rend[DATATYPE]Select().
Bohužel z nějakého důvodu (nezkoumal jsem jej) dojde k chybnému zvolení datového typu a vždy je volána funkce qb_rendCharSelect, která generuje SQL funkce pro text.

Workaround
Upozornění: jde pouze o workaround a nasazením nové verze může být vše jinak!
1/ V adresáři J2EE serveru (server ve kterém běží aplikace BI Publisheru) najděte soubor „qb_gensql.js“ (např. D:\ OracleBI\oc4j_bi\j2ee\home\applications\xmlpserver\xmlpserver\qb\qbfiles\qb_gensql.js)
2/ Soubor zazálohujte
3/ Soubor otevřete a najděte v něm funkci qb_rendCharSelect
4/ Doplňte agregační funkce (řádky zkopírujte z funkce qb_rendNumberSelect)
 5/ Soubor uložte
5/ Soubor uložte6/ Promažte lokální cache internetového prohlížeče a obnovte stránku Query Builderu – výsledkem je doplněný seznam SQL funkcí o funkce agregační

Erik Eckhardt.
Přihlásit se k odběru:
Příspěvky (Atom)