pondělí 22. prosince 2008

čtvrtek 18. prosince 2008
ODI - Integrace, transformace, mapování
V minulém díle jsme na základě zdrojového modelu vygenerovali model cílový. Nyní máme k dispozici zdroj i cíl a tudíž můžeme přistoupit k samotné integraci.
Podívejte se na video ukazující "step-by-step" postup jak v ODI provádět datové integrace, transformace, mapování.
jak v ODI provádět datové integrace, transformace, mapování.
Příště si ukážeme pokročilou funkcionalitu ODI, jako je Data Lineage, Workflow, Business pravidla pro datovou kvalitu nebo Webové služby.
Peter Hora (Semanta).
Podívejte se na video ukazující "step-by-step" postup
jak v ODI provádět datové integrace, transformace, mapování.Příště si ukážeme pokročilou funkcionalitu ODI, jako je Data Lineage, Workflow, Business pravidla pro datovou kvalitu nebo Webové služby.
Peter Hora (Semanta).
pondělí 15. prosince 2008
Zkušenosti s vytvářením, používaním a výkonností vlastních ukazatelů
V následujícím příspěvku uvádím zkušenosti s vytvářením, používaním a výkonností vlastních ukazatelů (počítaných sloupců). Příspěvek navazuje na článek Dva způsoby jak definovat vlastní výpočty (ukazatele) v Business modelu.
Vlastní ukazatel (např. početní operace nad hodnotami dvou sloupců) lze definovat následujícími způsoby:
1. Při návrhu reportu
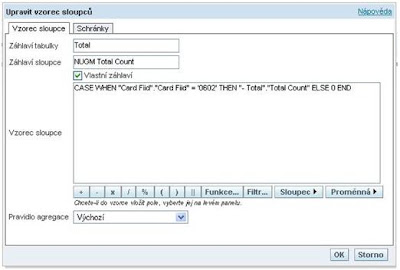
2. Pomocí metadat použitím logických sloupců
Ukázka výsledného dotazu:
WITH sawith0 AS
(SELECT DISTINCT t17101.is_on_us_flag AS c1, t1339.date_dt AS c2
FROM l1_owner.d_date t1339, l2_owner.a_stat_atm_agg t17101
WHERE (t1339.date_dt = t17101.audit_id)),
sawith1 AS
(SELECT SUM (t17101.amt_amt) AS c1, t1339.date_dt AS c2
FROM l1_owner.d_date t1339, l2_owner.a_stat_atm_agg t17101
WHERE (t1339.date_dt = t17101.audit_id)
GROUP BY t1339.date_dt)
SELECT DISTINCT CASE
WHEN sawith0.c2 IS NOT NULL
THEN sawith0.c2
WHEN sawith1.c2 IS NOT NULL
THEN sawith1.c2
END AS c1,
CASE
WHEN sawith0.c1 = '1'
THEN sawith1.c1
ELSE 0
END AS c2
FROM sawith0 FULL OUTER JOIN sawith1 ON sawith0.c2 = sawith1.c2
ORDER BY c1
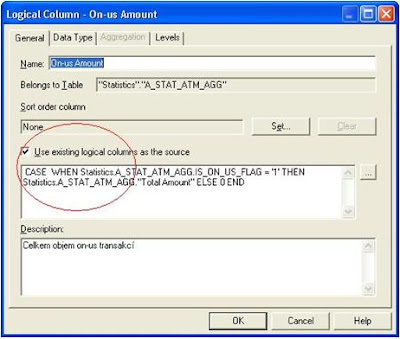
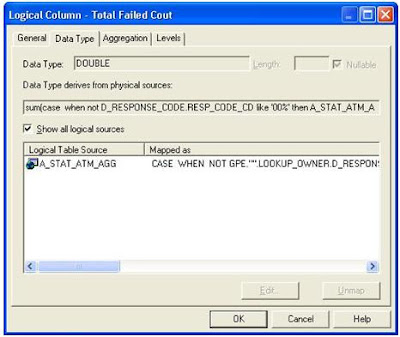
3. Pomocí metadat použitím fyzických sloupců
Ukázka výsledného dotazu:
SELECT t1339.date_dt AS c1,
SUM
(CASE
WHEN NOT t5199.resp_code_cd LIKE '00%'
THEN t17101.trn_cnt
ELSE 0
END
) AS c2
FROM l1_owner.d_date t1339,
lookup_owner.d_response_code t5199,
l2_owner.a_stat_atm_agg t17101
WHERE ( t1339.date_dt = t17101.audit_id
AND t5199.response_code_id = t17101.resp_cde_id
)
GROUP BY t1339.date_dt
ORDER BY c1
Závěr
Z výše uvedených informací vyplývá mé doporučení - pro definici vlastních ukazatelů používat v maximální míře fyzických sloupců:
Vlastní ukazatel (např. početní operace nad hodnotami dvou sloupců) lze definovat následujícími způsoby:
- Přímo při návrhu reportu
- Pomocí metadat použitím logických sloupců
- Pomocí metadat použitím fyzických sloupců
1. Při návrhu reportu
- Jednoduché a rychlé nastavení
- Vhodné při neopakovaném používání ukazatele (ukazatel je dostupný pouze v reportu kde je vytvořen)
- Samotný výpočet je prováděn nad agregovanými nebo detailními ukazateli (záleží na tom zda výchozí ukazatel měl v metadata vrstvě přednastavenu agregační funkci)
- Při nesprávném pochopení ukazatele z něhož se vychází a použití výpočetní funkce se může dojít k chybnému/nechtěnému výsledku (např. zprůměrovat již součtované ukazatele nebo viz. zde)
- Doporučuji používat pouze v případě, kdy zdrojové sloupce jsou také obsahem reportu
- V případě použití sloupců, které nejsou obsahem reportu má fyzický dotaz vysoký COST, který může narůst až o 6 řádů
- Tento způsob využijí spíše koncoví uživatelé pro Ad-hoc potřebu

2. Pomocí metadat použitím logických sloupců
- Výraz může odkazovat na sloupce/ukazatele v dané logické tabulce (i z více zdrojů)
- Nejprve je prováděna agregace, a pak výpočet nového sloupce což může ovlivnit správnost / nesprávnost výsledků – více viz. zde
- Pokud je odkazovaný sloupec obsahem reportu, tak je vše OK. Pokud není, pak fyzický dotaz má vysoký COST
- Ukazatel je pojmenován a delegován až do prezentační vrstvy – je možné jej opakovaně používat

Ukázka výsledného dotazu:
WITH sawith0 AS
(SELECT DISTINCT t17101.is_on_us_flag AS c1, t1339.date_dt AS c2
FROM l1_owner.d_date t1339, l2_owner.a_stat_atm_agg t17101
WHERE (t1339.date_dt = t17101.audit_id)),
sawith1 AS
(SELECT SUM (t17101.amt_amt) AS c1, t1339.date_dt AS c2
FROM l1_owner.d_date t1339, l2_owner.a_stat_atm_agg t17101
WHERE (t1339.date_dt = t17101.audit_id)
GROUP BY t1339.date_dt)
SELECT DISTINCT CASE
WHEN sawith0.c2 IS NOT NULL
THEN sawith0.c2
WHEN sawith1.c2 IS NOT NULL
THEN sawith1.c2
END AS c1,
CASE
WHEN sawith0.c1 = '1'
THEN sawith1.c1
ELSE 0
END AS c2
FROM sawith0 FULL OUTER JOIN sawith1 ON sawith0.c2 = sawith1.c2
ORDER BY c1
3. Pomocí metadat použitím fyzických sloupců
- Výraz může odkazovat na sloupce v připojených fyzických tabulkách (source)
- Nejprve je prováděn výpočet, a pak agregace nového sloupce což může ovlivnit správnost / nesprávnost výsledků – více viz. zde
- „Nepatrný“ COST fyzického dotazu a to ať jsou nebo nejsou zdrojové sloupce použity v reportu
- Ukazatel je pojmenován a delegován až do prezentační vrstvy – je možné jej opakovaně používat

Ukázka výsledného dotazu:
SELECT t1339.date_dt AS c1,
SUM
(CASE
WHEN NOT t5199.resp_code_cd LIKE '00%'
THEN t17101.trn_cnt
ELSE 0
END
) AS c2
FROM l1_owner.d_date t1339,
lookup_owner.d_response_code t5199,
l2_owner.a_stat_atm_agg t17101
WHERE ( t1339.date_dt = t17101.audit_id
AND t5199.response_code_id = t17101.resp_cde_id
)
GROUP BY t1339.date_dt
ORDER BY c1
Závěr
Z výše uvedených informací vyplývá mé doporučení - pro definici vlastních ukazatelů používat v maximální míře fyzických sloupců:
- Ukazatel je delegován až do prezentační vrstvy, takže jej lze opakovaně použít samotnými koncovými uživateli
- Není limitováno dalším způsobem použití (viz koncové dotazy)
- Nižší COST fyzického dotazu
Miroslav Petr (Adastra).
čtvrtek 11. prosince 2008
ODI - Založení cílového datového modelu (migrace modelů mezi různými technologiemi)
V předchozí části jsme v ODI pomocí funkcionality reverse-engineering načetli zdrojový datový model, ale cílový dat. model stále chybí.
Podívejte se na video ukazující "step-by-step" postup:
Příští díl bude o tom jak v ODI provádět samotné datové integrace, transformace, mapování mezi výše uvedenými modely.
Peter Hora (Semanta).
Podívejte se na video ukazující "step-by-step" postup:
- Jak lze v ODI na základě zdrojového dat. modelu vytvořit model cílový (neboli jak migrovat dat. modely mezi různými technologiemi)
- Jak v ODI vygenerovat a spustit databázové scripty pro fyzickou implementaci cílového dat. modelu
Příští díl bude o tom jak v ODI provádět samotné datové integrace, transformace, mapování mezi výše uvedenými modely.
Peter Hora (Semanta).
pondělí 8. prosince 2008
Současné zobrazení N nejlepších a N nejhorších
Na posledním školení jsem zákazníkům demonstroval příklad na výpis Top N a Ostatní. Padl dotaz, zda by šlo do téže sestavy vypsat současně "N" nejlepších a "N" nejhorších. Níže najdete řešení provedené nad demonstračními daty "Paint":
1. Vyberte Jeden sloupec s dimenzí a jeden faktový
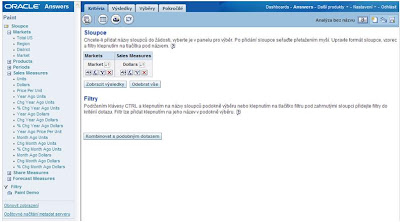
2. Stejný faktový sloupec přidejte ještě 3x
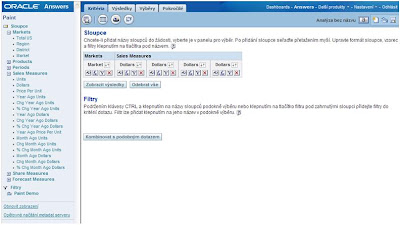
3. Jeho druhý výskyt upravte (Upravit sloupec)
4. Na témže sloupci nastavte třídění
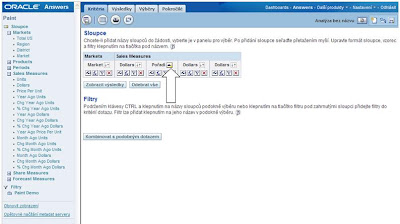
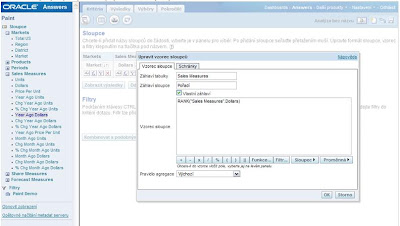
5. Následující sloupec bude sloužit pro určení toho, které z řádků patří mezi „Nejlepších 5“ a které mezi „Nejhorších 5“. Zvolte opět „Upravit sloupec“ (tlačítko fx) a použijte následující CASE příkaz:
CASE WHEN RANK("Sales Measures".Dollars) <= 5 THEN Markets.Market WHEN RANK("Sales Measures".Dollars) > MAX(RANK("Sales Measures".Dollars))-5 THEN Markets.Market ELSE 'Ostatní' END
V takto upraveném sloupci budou zobrazeny názvy poboček (hodnot dimenze) v případě, že jsou mezi prvními nebo posledními 5ti. V opačném případě bude v tomto sloupci hodnota „Ostatní“
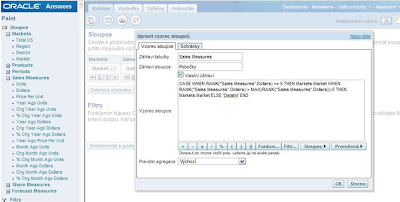
6. Poslední sloupec bude sloužit pro agregaci dle skupin „Nejlepších 5“, „Nejhorších 5“ a „Ostatní“. Klikněte opět na „Upravit sloupec“ a aplikujte následující vzorec:
CASE WHEN Rank("Sales Measures".Dollars) <= 5 THEN 'Nejlepších 5' WHEN Rank("Sales Measures".Dollars) > MAX(RANK("Sales Measures".Dollars))-5 THEN 'Nejhorších 5' ELSE 'Ostatní' END
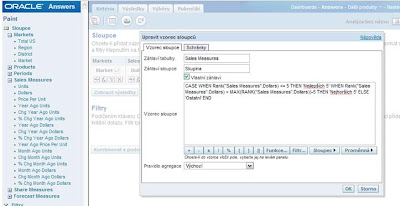
Takto nyní vypadá seznam sloupců ve výběru kritérií:

7. Nyní se přepněte do zobrazení kontingenční tabulky. Vylučte sloupce Pořadí a Market (původní dimenze). V části Míry ponechte pouze sloupec Dollars (faktová tabulka) a sloupec Skupina a Pobočky umístěte do sekce řádků:
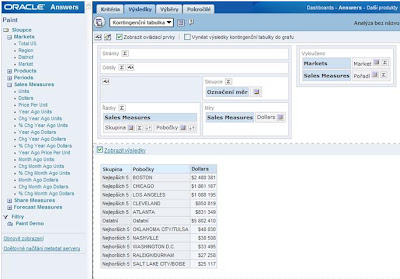
8. Sloupec skupina skryjte a nastavte pro něj součty (symbol ∑ - volba „za“). Také zvolte celkový součet v sekci řádky.
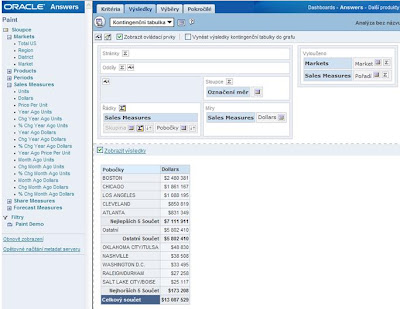
9. Graf pro takovéto společné výsledky nemá v podstatě smysl, neboť obvykle, jako i v tomto případě, jsou výsledky ze spodní části tabulky o několik řádů menší než ty z horní části. Pokud byste však chtěli graf použít, je možné výsledná data ještě filtrovat. Ukažme si možnost filtru pomocí výzvy sloupce:
a/ Na záložce „Výběry“ zvolte „Vytvořit výzvu – Výzva filtru sloupce“ a formulář vyplňte následovně (v prvním rozevíracím seznamu – Filtr podle sloupce - vyberte poslední hodnotu):
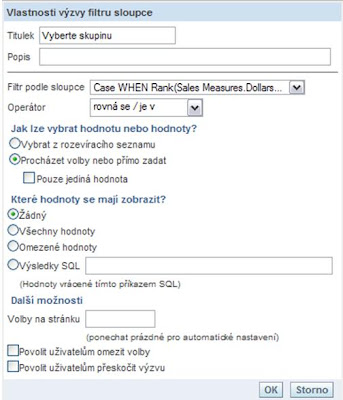
b/ Potvrďte OK. Test výzvy vypadá následovně (například):
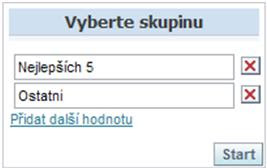
Hodnoty však nejdou nabídnout přímo, vzhledem k tomu, že jsou z vypočítaného sloupce. Musíte je tedy zadávat ručně. Pokud se překlepnete, žádná data nebudou vrácena.
c/ Výsledek pak vypadá takto:
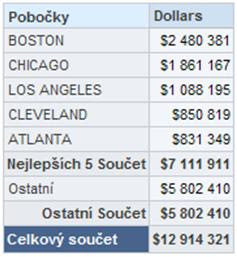
10. Přidejme tedy graf:
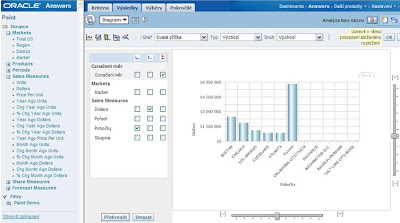
11. Graf zařaďte do složeného pohledu (Compound Layout) a otestujte sestavu prostřednictvím testovací výzvy:
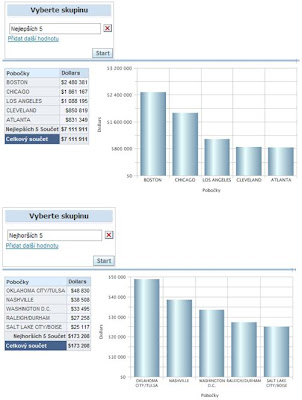
Mohli jste samozřejmě ještě použít dynamicky naplněnou hodnotu počtu nejlepších/nejhorších výsledků pomocí prezentační proměnné, jak je naznačeno v původním příkladu.
1. Vyberte Jeden sloupec s dimenzí a jeden faktový

2. Stejný faktový sloupec přidejte ještě 3x

3. Jeho druhý výskyt upravte (Upravit sloupec)

4. Na témže sloupci nastavte třídění

5. Následující sloupec bude sloužit pro určení toho, které z řádků patří mezi „Nejlepších 5“ a které mezi „Nejhorších 5“. Zvolte opět „Upravit sloupec“ (tlačítko fx) a použijte následující CASE příkaz:
CASE WHEN RANK("Sales Measures".Dollars) <= 5 THEN Markets.Market WHEN RANK("Sales Measures".Dollars) > MAX(RANK("Sales Measures".Dollars))-5 THEN Markets.Market ELSE 'Ostatní' END
V takto upraveném sloupci budou zobrazeny názvy poboček (hodnot dimenze) v případě, že jsou mezi prvními nebo posledními 5ti. V opačném případě bude v tomto sloupci hodnota „Ostatní“

6. Poslední sloupec bude sloužit pro agregaci dle skupin „Nejlepších 5“, „Nejhorších 5“ a „Ostatní“. Klikněte opět na „Upravit sloupec“ a aplikujte následující vzorec:
CASE WHEN Rank("Sales Measures".Dollars) <= 5 THEN 'Nejlepších 5' WHEN Rank("Sales Measures".Dollars) > MAX(RANK("Sales Measures".Dollars))-5 THEN 'Nejhorších 5' ELSE 'Ostatní' END

Takto nyní vypadá seznam sloupců ve výběru kritérií:

7. Nyní se přepněte do zobrazení kontingenční tabulky. Vylučte sloupce Pořadí a Market (původní dimenze). V části Míry ponechte pouze sloupec Dollars (faktová tabulka) a sloupec Skupina a Pobočky umístěte do sekce řádků:

8. Sloupec skupina skryjte a nastavte pro něj součty (symbol ∑ - volba „za“). Také zvolte celkový součet v sekci řádky.

9. Graf pro takovéto společné výsledky nemá v podstatě smysl, neboť obvykle, jako i v tomto případě, jsou výsledky ze spodní části tabulky o několik řádů menší než ty z horní části. Pokud byste však chtěli graf použít, je možné výsledná data ještě filtrovat. Ukažme si možnost filtru pomocí výzvy sloupce:
a/ Na záložce „Výběry“ zvolte „Vytvořit výzvu – Výzva filtru sloupce“ a formulář vyplňte následovně (v prvním rozevíracím seznamu – Filtr podle sloupce - vyberte poslední hodnotu):

b/ Potvrďte OK. Test výzvy vypadá následovně (například):

Hodnoty však nejdou nabídnout přímo, vzhledem k tomu, že jsou z vypočítaného sloupce. Musíte je tedy zadávat ručně. Pokud se překlepnete, žádná data nebudou vrácena.
c/ Výsledek pak vypadá takto:

10. Přidejme tedy graf:

11. Graf zařaďte do složeného pohledu (Compound Layout) a otestujte sestavu prostřednictvím testovací výzvy:

Mohli jste samozřejmě ještě použít dynamicky naplněnou hodnotu počtu nejlepších/nejhorších výsledků pomocí prezentační proměnné, jak je naznačeno v původním příkladu.
Petr Zeman (OKsystem)
čtvrtek 4. prosince 2008
ODI - Reverse-engineering stávajícího datového modelu
Dalším krokem po založení Projektu a naimportovaní Knowledge modulů je načtení zdrojových/cílových dat. modelů (tj. tabulek, pohledů, atd.), které budou zahrnuty do samotné integrace.
Podívejte se na video ukazující "step-by-step" postup jak v ODI provést reverse-engineering stávajícího datového modelu.
Příští díl bude o tom jak v ODI na základě zdrojového dat. modelu vytvořit model cílový (neboli jak migrovat datové modely mezi různými technologiemi).
Peter Hora (Semanta).
Podívejte se na video ukazující "step-by-step" postup
jak v ODI provést reverse-engineering stávajícího datového modelu.Příští díl bude o tom jak v ODI na základě zdrojového dat. modelu vytvořit model cílový (neboli jak migrovat datové modely mezi různými technologiemi).
Peter Hora (Semanta).
pondělí 1. prosince 2008
Chybějící BI Office Add-in – může se to stát i Vám
Nedávno jsem měl prezentaci, na které se měla ukazovat funkcionalita komponenty BI Office Add-in pro MS Excel a MS PowerPoint.
Před prezentací vždy kontroluji, že vše funguje .... a ejhle BI Office Add-in pro MS PowerPoint chybí! (ale BI Add-in pro MS Excel existoval a fungoval správně).
Co s tím? Rychle jsem celý BI Office Add-in reinstaloval ... Add-in pro Excel fungoval, ale Add-in pro PowerPoint stále chyběl. Rychle jsem celý BI Office Add-in odinstaloval ... restartoval PC .... nainstaloval .... restartoval PC ... výsledek BI Add-in pro Excel fungoval, ale BI Add-in pro PowerPoint stále chyběl :(
Prohledal jsem web a na nějakém MS fóru jsem našel, že MS Office v nějakých případech vypne integrované Add-ins.
Opětovně zapnout Add-in v MS Office můžete pomocí menu Help > About MS Office ... > Disabled Items ... > vyberete Add-in z menu > a zvolíte Enable.
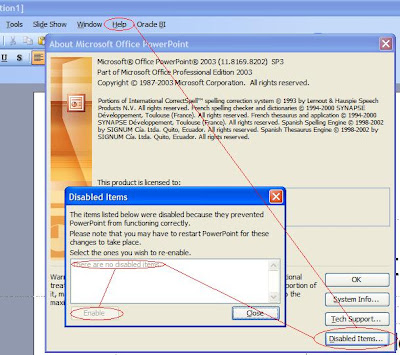
Před prezentací vždy kontroluji, že vše funguje .... a ejhle BI Office Add-in pro MS PowerPoint chybí! (ale BI Add-in pro MS Excel existoval a fungoval správně).
Co s tím? Rychle jsem celý BI Office Add-in reinstaloval ... Add-in pro Excel fungoval, ale Add-in pro PowerPoint stále chyběl. Rychle jsem celý BI Office Add-in odinstaloval ... restartoval PC .... nainstaloval .... restartoval PC ... výsledek BI Add-in pro Excel fungoval, ale BI Add-in pro PowerPoint stále chyběl :(
Prohledal jsem web a na nějakém MS fóru jsem našel, že MS Office v nějakých případech vypne integrované Add-ins.
Opětovně zapnout Add-in v MS Office můžete pomocí menu Help > About MS Office ... > Disabled Items ... > vyberete Add-in z menu > a zvolíte Enable.

Erik Eckhardt.
Přihlásit se k odběru:
Příspěvky (Atom)