BI/DW Demo Server je po týdenním stěhování opět k dispozici. Pozor, došlo ke změně jeho IP adresy! Nyní je dostupný na http://85.70.78.197
Omlouváme se za vzniklé komplikace při jeho nedostupnosti a děkujeme za pochopení.
Erik Eckhardt
čtvrtek 28. ledna 2010
Prezentace ze semináře Opravdu vidíte všechny možnosti příjmů?
Dnes dopoledne v prostorách Oracle Czech proběhl seminář na téma "Opravdu vidíte všechny možnosti příjmů?".
Děkujeme všem účastníkům a prezentujícím!
Prezentace ze semináře:
Děkujeme všem účastníkům a prezentujícím!
Prezentace ze semináře:
pondělí 25. ledna 2010
Formát numerických položek v BI Publisheru, nezávislých od nastavení Report Locale pro daného uživatele
Při návrhu sestav v BI Publisheru u našeho zákazníka jsme dostali požadavek na formátování numerických položek v sestavách – a to konkrétně na fixní použití oddělovačů řádů a desetinného místa (oddělovač řádů "mezera" a oddělovač desetinných míst "čárka") a to bez ohledu na nastavení uživatelských preferencí (Report Locale).
Samozřejmě BI Publisher umožňuje formátovat numerické položky, dokonce 2 způsoby - tak jak uvádí standardní BI Publisher dokumentace:
Jak ale zajistit, aby byl použit vždy fixní znak pro oddělovače, nezávisle od nastavení locales?
Samozřejmě první metodou, která mě napadla je, provést konverzi numerických položek na řetězec již v rámci definice SQL dotazu pro datový zdroj sestavy v BI Publisheru za použití Oracle konverzní funkce TO_CHAR, kde mám „pod kontrolou“ i použití znaků oddělovačů u konvertovaného řetezce z čísla (TO_CHAR(SLOUPEC,'999G999D99', 'NLS_NUMERIC_CHARACTERS = '', ''') – kde první znak v parametru NLS_NUMERIC_CHARACTERS představuje oddělovač desetinného místa, druhý znak oddělovač řádů). Nevýhodou tohoto řešení je, že pokud takto již na úrovni SQL dotazu změníte datový typ sloupce z NUMBER na znakový, nemůžete v rámci definice templatu sestavy s touto položkou operovat jako s číslem a tím pádem provádět s touto položkou agregační operace (součty, subsoučty za skupiny), což je přesně to, co by nám při definici sestav chybělo.
Zapátral jsem tedy na všemocném Internetu a v rámci diskusního fóra pro BI Publisher na Oracle Technology Network jsem našel příspěvek, který se zdál, že náš problém řeší (http://forums.oracle.com/forums/thread.jspa?threadID=603514&tstart=0).
Po pár vyzkoušení metodou pokus-omyl jsme nakonec (použitím této metody) dospěli ke kýženému výsledku – jelikož má toto řešení určité aspekty, na které je potřeba si dát pozor, stručně toto řešení (i s upozorněním, co je potřeba si pohlídat) popíšu.
1. Nejprve je nutné v rámci templatu sestavy (např. hned na začátku templatu) následující xsl tag:

Definujete ho jako pole BI Publisheru , kde v kódu použijete definici xsl tagu :
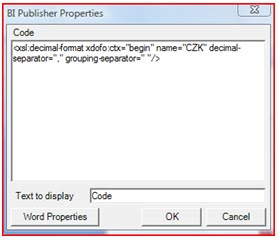
2. Pro numerickou položku, na kterou chcete aplikovat formátování s použitím oddělovačů, definovaném v xsl tagu pak použijete následující kód :
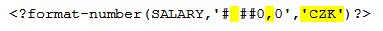
Důležité při sestavování formátové masky je to, aby jste pro znaky oddělovačů řádů/desetinných míst uvedly stejné znaky, jaké jste definovali v rámci xsl tagu (a samozřejmě i název – CZK)
Výsledkem je pak kýžené použití oddělovačů, nezávislé od nastavení prostředí:
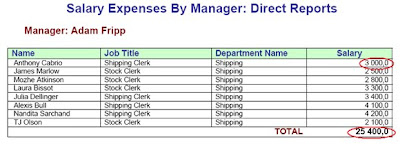
Michal Zima (BI&DWH Architekt, Teura s.r.o.)
Samozřejmě BI Publisher umožňuje formátovat numerické položky, dokonce 2 způsoby - tak jak uvádí standardní BI Publisher dokumentace:
- Microsoft Word's Native number format mask
- Oracle's format-number function
Jak ale zajistit, aby byl použit vždy fixní znak pro oddělovače, nezávisle od nastavení locales?
Samozřejmě první metodou, která mě napadla je, provést konverzi numerických položek na řetězec již v rámci definice SQL dotazu pro datový zdroj sestavy v BI Publisheru za použití Oracle konverzní funkce TO_CHAR, kde mám „pod kontrolou“ i použití znaků oddělovačů u konvertovaného řetezce z čísla (TO_CHAR(SLOUPEC,'999G999D99', 'NLS_NUMERIC_CHARACTERS = '', ''') – kde první znak v parametru NLS_NUMERIC_CHARACTERS představuje oddělovač desetinného místa, druhý znak oddělovač řádů). Nevýhodou tohoto řešení je, že pokud takto již na úrovni SQL dotazu změníte datový typ sloupce z NUMBER na znakový, nemůžete v rámci definice templatu sestavy s touto položkou operovat jako s číslem a tím pádem provádět s touto položkou agregační operace (součty, subsoučty za skupiny), což je přesně to, co by nám při definici sestav chybělo.
Zapátral jsem tedy na všemocném Internetu a v rámci diskusního fóra pro BI Publisher na Oracle Technology Network jsem našel příspěvek, který se zdál, že náš problém řeší (http://forums.oracle.com/forums/thread.jspa?threadID=603514&tstart=0).
Po pár vyzkoušení metodou pokus-omyl jsme nakonec (použitím této metody) dospěli ke kýženému výsledku – jelikož má toto řešení určité aspekty, na které je potřeba si dát pozor, stručně toto řešení (i s upozorněním, co je potřeba si pohlídat) popíšu.
1. Nejprve je nutné v rámci templatu sestavy (např. hned na začátku templatu) následující xsl tag:



Výsledkem je pak kýžené použití oddělovačů, nezávislé od nastavení prostředí:

čtvrtek 21. ledna 2010
Opravdu vidíte všechny možnosti příjmů?
Neustále okolo sebe slyšíme slovo „krize“. Pro někoho krize znamená šetřit, pro někoho příležitost podívat se, jestli nemohu něco získat. Ani jedno není snadné.
Protože chceme získat, tak se podívejme, jestli jsme na něco nezapomněli. Co když existuje možnost, kterou teď pouhým okem nevidíme nebo o ní nevíme? Dovedeme včas a bez chyb získat informaci z velkého množství dat, která máme k dispozici? Předáváme snadno a přesně informace svým kolegům, obchodníkům či zákazníkům?
Pokud hledáte odpovědi na podobné otázky nebo Vás napadají ještě další, potom přijďte 28. ledna 2010 mezi nás. Připravili jsme pro Vás odborný seminář, na kterém se podělíme o způsoby jak hledat nové možnosti, analyzovat data a rozhodovat se na základě faktů.
Ne teorie, ale konkrétní příklady z projektů!
Agenda
9:30 - Registrace
9:45 - Zahájení
10:00 - Případová studie – Dohled nad výnosovými procesy ve společnosti Vodafone
10:45 - Případová studie – Obchodní controlling ve finanční skupině Wüstenrot
11:30 - Panelová diskuse
12:00 - Společný oběd
13:00 - Zakončení
Kdy
Čtvrtek 28. ledna 2010
9:30 – 13:00 hodin
Oracle Czech, Škrétova 12, Praha 2
Registrace
Kapacita je omezená, proto se prosím v případě zájmu registrujte co nejdříve na adrese vendula.fleissigova@oracle.com
Protože chceme získat, tak se podívejme, jestli jsme na něco nezapomněli. Co když existuje možnost, kterou teď pouhým okem nevidíme nebo o ní nevíme? Dovedeme včas a bez chyb získat informaci z velkého množství dat, která máme k dispozici? Předáváme snadno a přesně informace svým kolegům, obchodníkům či zákazníkům?
Pokud hledáte odpovědi na podobné otázky nebo Vás napadají ještě další, potom přijďte 28. ledna 2010 mezi nás. Připravili jsme pro Vás odborný seminář, na kterém se podělíme o způsoby jak hledat nové možnosti, analyzovat data a rozhodovat se na základě faktů.
Ne teorie, ale konkrétní příklady z projektů!
Agenda
9:30 - Registrace
9:45 - Zahájení
10:00 - Případová studie – Dohled nad výnosovými procesy ve společnosti Vodafone
10:45 - Případová studie – Obchodní controlling ve finanční skupině Wüstenrot
11:30 - Panelová diskuse
12:00 - Společný oběd
13:00 - Zakončení
Kdy
Čtvrtek 28. ledna 2010
9:30 – 13:00 hodin
Oracle Czech, Škrétova 12, Praha 2
Registrace
Kapacita je omezená, proto se prosím v případě zájmu registrujte co nejdříve na adrese vendula.fleissigova@oracle.com
pondělí 18. ledna 2010
NQCmd na Linuxu
Užitečná utilitka NQCmd, která umí před ODBC poslat BI Serveru nějaký select nebo příkaz, má v prostředí Linuxu/Unixu několik specifik použití oproti Windows platformám. Zde jsou dvě nejdůležitější:
1. Init nastavení
Proto, aby šlo utilitku vůbec pustit, je třeba před samotným zavoláním nqcmd spustit nejprve tuto sadu příkazů, které patřičně nastaví prostředí:
export SAHOME=/srv/oracle
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$SAHOME/OracleBI/odbc/lib:$SAHOME/OracleBI/server/Bin
. $SAHOME/OracleBI/setup/common.sh
. $SASYSINITSCRIPT
Bez tohoto nastavení neumí NQCmd najít odbc knihovnu a nelze spustit.
2. Čeština
Asi nejčastější využití utilitky je na management cache. Její základní volání vypadá nějak takto:
./nqcmd -d AnalyticsWeb -u uzivatel -p heslo -q -s /srv/oracle/adm/feed_cache.sql
Soubor feed_cache.sql obsahuje sadu logických selectů do BI Serveru (viz Advanced záložka v BI Answers). V případě, že se v názvech sloupců prezentační vrstvy vyskytují české znaky, pravděpodobně dojde k chybě “Unresolved column“. Utilitka nenamapuje češtinu ze souboru na češtinu v metadatech.
Proto, aby správně fungovala čeština, je třeba upravit soubor .../OracleBI/setup/odbc.ini a změnit zde parametr IANAAppCodePage ze 4 (iso8859-1) na 5 (iso8859-2). Poté stačí mít soubor feed_cache.sql kódován iso8859-2 a vše funguje bez problémů.
1. Init nastavení
Proto, aby šlo utilitku vůbec pustit, je třeba před samotným zavoláním nqcmd spustit nejprve tuto sadu příkazů, které patřičně nastaví prostředí:
export SAHOME=/srv/oracle
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$SAHOME/OracleBI/odbc/lib:$SAHOME/OracleBI/server/Bin
. $SAHOME/OracleBI/setup/common.sh
. $SASYSINITSCRIPT
Bez tohoto nastavení neumí NQCmd najít odbc knihovnu a nelze spustit.
2. Čeština
Asi nejčastější využití utilitky je na management cache. Její základní volání vypadá nějak takto:
./nqcmd -d AnalyticsWeb -u uzivatel -p heslo -q -s /srv/oracle/adm/feed_cache.sql
Soubor feed_cache.sql obsahuje sadu logických selectů do BI Serveru (viz Advanced záložka v BI Answers). V případě, že se v názvech sloupců prezentační vrstvy vyskytují české znaky, pravděpodobně dojde k chybě “Unresolved column“. Utilitka nenamapuje češtinu ze souboru na češtinu v metadatech.
Proto, aby správně fungovala čeština, je třeba upravit soubor .../OracleBI/setup/odbc.ini a změnit zde parametr IANAAppCodePage ze 4 (iso8859-1) na 5 (iso8859-2). Poté stačí mít soubor feed_cache.sql kódován iso8859-2 a vše funguje bez problémů.
Jakub Genža (Capgemini Sophia)
čtvrtek 14. ledna 2010
Nová verze ODI - Cumulative Patch Set 10.1.3.5.5
10. prosince 2009 byl uvolněn kumulativní patch pro ODI, který jej povyšuje na verzi 10.1.3.5.5. Patch lze aplikovat na všechny verze počínaje základní 10.1.3.5.0, tj. 10.1.3.5.0_01, 10.1.3.5.0_02, 10.1.3.5.1, 10.1.3.5.1_01, 10.1.3.5.2, 10.1.3.5.3 a 10.1.3.5.4
Patch je ke stažení z Oracle Support, pod označením 9200535 - link na patch najdete zde. Novinky verze 10.1.3.5.5. a 10.1.3.5.4 najdete níže, ostatní viz. zde.
eec.
Patch je ke stažení z Oracle Support, pod označením 9200535 - link na patch najdete zde. Novinky verze 10.1.3.5.5. a 10.1.3.5.4 najdete níže, ostatní viz. zde.
Version 10.1.3.5.5
New/Modified Objects
The following KMs have been modified or added in this version:
LKM Hyperion Essbase METADATA to SQL - Modified
IKM SQL to Hyperion Essbase (DATA) - Modified
RKM SAP ERP - Modified
LKM SAP ERP to Oracle (SQLLDR) - Modified
RKM Salesforce.com - Modified
Bugs Fixed
7274910 - Killing a Session generates the following error on DB2 UDB repositories: "DB2 SQL error: SQLCODE: -408, SQLSTATE: 42821, SQLERRMC: I_TXT_STEP_MESS".
8446089 - Master Repository upgrade resets the data servers' URLs.
8529169 - "Class not registered" error while loading metadata into Hyperion Financial Management classic application using an 64-Bit HFM Client.
A new 64-bit driver (HFMDriver64.dll) has been added to the /oracledi/drivers directory. To use this driver on a 64-Bit platform with a 64-Bit HFM Client installed, rename HFMDriver.dll as HFMDriver32.dll and rename HFMDriver64.dll as HFMDriver.dll.8636504 - Customized reverse-engineering using RKM Salesforce.com fails with the error "UNKNOWN_EXCEPTION: Destination URL not reset. The URL returned from login must be set in the SforceService" .
8640312 - SNP_EXP_TXT still contains records for session variables after a log purge.
8713986 - Consolidation attribute "^" (Never Consolidate - Added in Essbase 9.3.1) is not handled in the Essbase KM. The Extract Metadata step fails with error "No_matching_Enum_found".
8844655 - Metadata Navigator Data Lineage feature fails to work in headless mode.
8912703 - When an Essbase member is rejected due to error "3303: Member not found in database" the log does not indicate which member caused the record to be rejected.
8988790 - ODI internal IDs reset to 0 once its limit is reached causing repository corruption. In this version internal IDs are no longer automatically reset to zero.
8989114 - Users having only View privilege cannot see procedure and KM lines and receive the error: "You are not authorized to Edit the Object"
9076431 - Historized variables do not return the latest variable value if an internal ID (SNP_VAR_DATA.I_VAL) reset was performed for variable values (bug 8988790). This version solves this problem by taking the latest value based on value creation date and not the internal ID.
9080483 - Essbase Interface fails with "ImportError: No module named hyperion" on the "Prepare for loading step" when loading ASO/BSO data into Essbase.
9126706 - Metadata Navigator does not start after deploying the oracledimn.war from the ODI patch 10.1.3.5.3
Version 10.1.3.5.4
New/Modified Objects
A new version of the CDCRTVJRN RPG program for CDC on iSeries is delivered with this patch.
The following KMs have been modified or added in this version:
- LKM File to Netezza (NZLOAD) - New
LKM MSSQL to Oracle (BCP/SQLLDR) - New
RKM MSSQL - New
RKM Oracle - Modified
LKM File to Oracle - Modified
- The following Teradata KMs have been modified to generate temporary tables with a "NO PRIMARY INDEX" clause. This is configured by setting the PRIMARY_INDEX KM option to NOPI.
LKM File to Teradata (TTU)
LKM SQL to Teradata (TTU)
CKM Teradata
IKM File to Teradata (TTU)
IKM SQL to Teradata (TTU)
IKM Teradata Control Append
The following technologies have been modified or added in this version:
SAP ABAP
Bugs Fixed
6447278 - RKM Oracle doesn't import the check constraints of tables.
8550987 - LKM File to Oracle (SQLLDR) fails with error: "Field in data file exceeds maximum length" when loading a file that contains a string longer than 255 characters.
- 8605840 - Model or Model folder creation fails with java.lang.stackoverflowerror if the user is not a supervisor user having metadata admin profile.
8854189 - ODI Master Repository import incorrectly deletes existing data server connections if the insert_update mode is selected.
8871204 - Master Repository import aborts when user expands a node in Topology Manager.
8899683 - JKM DB2 400 Simple (Journal) does not handle uncommitted transaction with CDCRTVJRN.
8904234 - Sessions continue to execute even if the Master Repository connection is terminated.
8917148 - Timestamp datatypes loose time precision after the millisecond when data is loaded via the agent.
eec.
pondělí 11. ledna 2010
Data Mart pro ČNB výkaznictví
1. Popis oblasti
Data mart pro ČNB výkaznictví jinak také Regulatory reporting data mart (dále jen RRDM) vznikl na základě požadavku na vytvoření hybridního data martu od oddělení Regulatorní výkaznictví Banky. Data mart je stavěn jako nadstavba již existujícího datového skladu. V prvním kroku bylo rozhodnuto, že nově budovaný data mart bude přebírat data, která do DWH již nyní dodávají, následující systémy:
Oddělení regulatorního výkaznictví v současné době provozuje, na DWH zcela nezávislý, data mart, který slouží pro potřeby tvorby reportů pro ČNB. Tento data mart je plněn daty z různých zdrojových systémů v různé podobě a tvoří datovou základnu pro systém DaMiAs.
Data Migration Asistant (DaMiAs) je soubor programů plnících funkci rozhraní a zároveň datové pumpy, kdy vstupní část je závislá na konkrétní struktuře dat v datovém skladu. Výstupem jsou pak zpracované údaje importované do jednotné datové základny SDI.
Požadavek na nový, částečně závislý, data mart vznikl, aby došlo především k odstranění negativních důsledků aktuálního stavu:
3. Návrh řešení
Navrhované řešení RRDM je zobrazeno na následujícím obrázku.
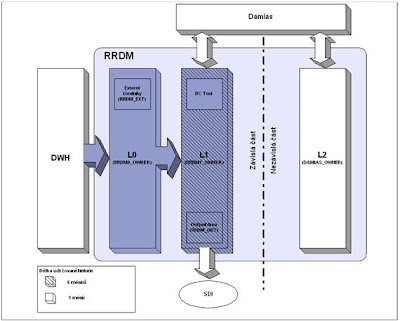
Jedná se o hybridní řešení data martu, kdy struktury tabulek jsou orientované výkaznicky, tj. tabulky jsou vlastně časové řezy, vždy k ultimo měsíce. RRDM se skládá ze tří vrstev:
Závislá část RRDM (datově závislá na DWH) zahrnuje vrstvy L0 a L1. Nezávislou část (plněná a spravovaná prostřednictvím systému DaMiAs) tvoří vrstva L2. Části, na obrázku vybarvené odstíny modré barvy, budou vytvářeny a budou plněny v rámci vývoje nového inkrementu DWH.
Návrh logického datového modelu pro vrstvy L0 a L1 je znázorněn na ER diagramu:
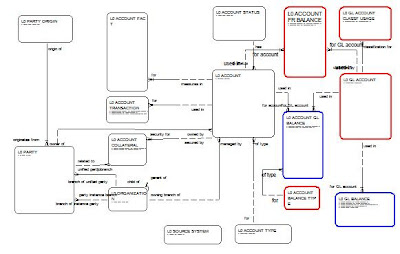
Vrstva L1 je, z hlediska entit a jejich vazeb, téměř stejná jako L0 a liší se pouze o barevně zvýrazněné entity. Červeně označené v L1 chybí, modře označené mají v L1 jinou strukturu (liší se v atributech a případně granularitou záznamů).
3.1 Vrstva L0
Popis
Jedná se vrstvu, ve které jsou umístěny tabulky, které jsou přímo plněné z jediného zdroje – DWH. Součástí této vrstvy může být i oblast externích dat (RRDM_EXT), což jsou číselníky a převodové můstky spravované manuálně a používané pouze pro RRDM. V tomto inkrementu oblast externích dat nebude realizována, neboť nevznikl žádný požadavek na číselník pro RRDM
Tabulky jsou členěny, tam kde to má význam, podle typu účtu nebo zdroje klienta
Vrstva může obsahovat pomocné – stage tabulky pro optimalizaci zpracování dat.
Zpracování dat
Data se do této vrstvy vkládají jednou měsíčně, vždy po uzavření měsíce v DWH pro daný zdrojový systém. Data se nahrávají automaticky po jednotlivých zdrojových systémech samostatným procesem pro každý zdroj. Při nahrávání se stávající data nejprve vymažou a potom se nově vkládají.
Historie dat
Je udržována datová historie pouze pro jeden – aktuální měsíc. Data nejsou archivována.
Přístup uživatelů
Do této vrstvy mají přístup všichni uživatelé s právem pro výběr dat (select) bez možnosti data měnit. Tito uživatelé mají roli RRDM0_ALL_SELECT. Data zde lze upravovat pouze opětovným spuštěním standardního procesu nahrávání dat. (role RRDM0_ALL_CHANGE).
Umístění
Tabulky této vrstvy jsou umístěny pod uživatelem RRDM0_OWNER.
3.2 Vrstva L1
Popis
Vrstva L1 je plněna ETL procesem z vrstvy L0. Tato vrstva dále obsahuje výstupní tabulky z DaMiAs, která je dále využívána reportovacím systémem SDI. Součástí této vrstvy bude Data Correction Tool (DCT), což je pro Banku vyvinutý nástroj na opravu dat.
Tabulky jsou členěny stejně jako v L0, obsahují však navíc členění podle času – měsíční členění.
V této vrstvě budou také definovány tabulky OUT_GL_STAV_DETAIL a OUT_GL_STAV, do kterých bude systém DaMiAs vkládat data. Struktury těchto tabulek a indexy tabulky definuje Oddělení regulatorního výkaznictví. Tabulky budou mít členění podle času. Partition bude definována jako měsíční, vždy k ultimo měsíce.
Zpracování dat
Data jsou plněna na měsíční bázi. Kromě tabulek GL_ACCOUNTS, ACCOUNT FR BALANCE a GL_ACCOUNT_CLASSF_USAGES, které v L1 zcela chybí a tabulek ACCOUNT_GL_BALANCES a GL_BALANCES, které se v některých atributech odlišují, jsou tabulky shodné s vrstvou L0. Data v L1 mohou být upravována:
Historie dat
Požadavkem uživatelů je mít data dostupná po dobu 6 měsíců přímo v databázi a po dobu 10 let z offline zálohy. Obnova ze zálohy starší 6 měsíců by se prováděla jen na základě požadavku Oddělení regulatorního výkaznictví. Pro offline zálohu je navrženo rozšíření stávajícího Operátorského prostředí DWH o možnosti archivace databáze do formátu Oracle Export nebo Oracle Data Pump. Takto extrahované archivační soubory budou uloženy v archivačním systému Banky. Po dobu, než bude vyvinuta DWH Archivace, nebudou data v RRDM mazána. Předpokládá se nasazení DWH Archivace v průběhu jednoho roku, tj. data v L1 by měla být maximálně za 12 měsíců.
Přístup uživatelů
Do této vrstvy mají přístup všichni uživatelé s právem pro výběr dat (select) bez možnosti data měnit. Tito uživatelé mají roli RRDM1_ALL_SELECT. Data zde lze upravovat pouze opětovným spuštěním standardního procesu nahrávání dat. (role RRDM1_ALL_CHANGE) nebo skriptem resp. DCT s rolí RRDM1_DC_CHANGE
Umístění
Tabulky této vrstvy jsou umístěny pod uživatelem RRDM1_OWNER. Výstupní tabulky DaMiAs potom pod uživatelem OUT_OWNER.
3.3 Vrstva L2
Popis
Vrstva L2, jedná se o nezávislou část RRDM, bude spravována a řízena systémem DaMiAs. Do této vrstvy budou data nahrávaná z vrstvy L1 a dalších systémů, které budou ve správě administrátora DaMiAs. Pro tuto vrstvu bude vyčleněn tabulkový prostor 100 GB.
Zpracování dat
Data budou zpracovávána pouze prostřednictvím systému DaMiAs. Postupy a metody tohoto zpracování nejsou součástí tohoto dokumentu a ani nejsou součástí tohoto řešení.
Historie dat
Délka historie dat je řízena systémem DaMiAs.
Přístup uživatelů
Nepředpokládá se, že do této vrstvy budou přímo přistupovat uživatelé. Veškerá správa se bude provádět prostřednictvím DaMiAs, který bude využívat vlastníka této vrstvy DAMIAS_OWNER.
Umístění
Tabulky této vrstvy budou umístěny pod uživatelem DAMIAS_OWNER
4. Změny prováděné v DWH
Tato koncepce řešení RRDM nevyžaduje žádné zásadní změny v ODS/DWH kromě následujících:
5. Požadavky na DaMiAs
Pro správnou práci s výstupními OUT tabulkami ve vrstvě L1 musí systém umožňovat tyto aktivity:
Rušení partition bude prováděno v rámci procesu Purge strategie RRDM.
V případě požadavku na změnu struktury OUT tabulky, bude postupována standardním změnovým řízením.
V rámci akceptačních testů musí proběhnout integrační testy s DaMiAs.
Mezi RRDM a „starou“ DaMiAs databází bude vytvořen veřejný databázový link Pro využívání tohoto linku musí být na cílové straně vytvořen uživatel se stejným jménem a heslem jako na straně RRDM.
6. Shrnutí řešení
Celá koncepce hybridního data martu je navržena tak, aby byla snadno rozšiřitelná o další zdrojové systémy, což se i v dalších inkrementech předpokládá. Pro zpětné ověření dat bude, po dobu než dojde k převedení agendy všech zdrojových systému, která reporting vyžaduje, do RRDM zpřístupněno původní „starý“ DaMiAs data mart to prostřednictvím databázového linku.
Obecné výhody navrženého řešení jsou:
Data mart pro ČNB výkaznictví jinak také Regulatory reporting data mart (dále jen RRDM) vznikl na základě požadavku na vytvoření hybridního data martu od oddělení Regulatorní výkaznictví Banky. Data mart je stavěn jako nadstavba již existujícího datového skladu. V prvním kroku bylo rozhodnuto, že nově budovaný data mart bude přebírat data, která do DWH již nyní dodávají, následující systémy:
- Systém kreditních karet
- Systém pro běžné privátní klientské účty
- Hlavní kniha – Finanční systém Banky
- Klientský pobočkový systém
- Externí data – Správa externích dat DWH
- Finanční rekonciliace – Rekonciliace finančních dat ze zdrojových systémů a Hlavní knihy v DWH
Oddělení regulatorního výkaznictví v současné době provozuje, na DWH zcela nezávislý, data mart, který slouží pro potřeby tvorby reportů pro ČNB. Tento data mart je plněn daty z různých zdrojových systémů v různé podobě a tvoří datovou základnu pro systém DaMiAs.
Data Migration Asistant (DaMiAs) je soubor programů plnících funkci rozhraní a zároveň datové pumpy, kdy vstupní část je závislá na konkrétní struktuře dat v datovém skladu. Výstupem jsou pak zpracované údaje importované do jednotné datové základny SDI.
Požadavek na nový, částečně závislý, data mart vznikl, aby došlo především k odstranění negativních důsledků aktuálního stavu:
- Business intelligence architektura Banky nemá jednotnou platformu,
- Zdroje nejsou vynakládány efektivně – je nakupován dodatečný hardware, v databázích jsou uložena duplicitní data,
- Systémy nejsou podporovány ze strany úseku IT vývoj
3. Návrh řešení
Navrhované řešení RRDM je zobrazeno na následujícím obrázku.

Jedná se o hybridní řešení data martu, kdy struktury tabulek jsou orientované výkaznicky, tj. tabulky jsou vlastně časové řezy, vždy k ultimo měsíce. RRDM se skládá ze tří vrstev:
Závislá část RRDM (datově závislá na DWH) zahrnuje vrstvy L0 a L1. Nezávislou část (plněná a spravovaná prostřednictvím systému DaMiAs) tvoří vrstva L2. Části, na obrázku vybarvené odstíny modré barvy, budou vytvářeny a budou plněny v rámci vývoje nového inkrementu DWH.
Návrh logického datového modelu pro vrstvy L0 a L1 je znázorněn na ER diagramu:

Vrstva L1 je, z hlediska entit a jejich vazeb, téměř stejná jako L0 a liší se pouze o barevně zvýrazněné entity. Červeně označené v L1 chybí, modře označené mají v L1 jinou strukturu (liší se v atributech a případně granularitou záznamů).
3.1 Vrstva L0
Popis
Jedná se vrstvu, ve které jsou umístěny tabulky, které jsou přímo plněné z jediného zdroje – DWH. Součástí této vrstvy může být i oblast externích dat (RRDM_EXT), což jsou číselníky a převodové můstky spravované manuálně a používané pouze pro RRDM. V tomto inkrementu oblast externích dat nebude realizována, neboť nevznikl žádný požadavek na číselník pro RRDM
Tabulky jsou členěny, tam kde to má význam, podle typu účtu nebo zdroje klienta
Vrstva může obsahovat pomocné – stage tabulky pro optimalizaci zpracování dat.
Zpracování dat
Data se do této vrstvy vkládají jednou měsíčně, vždy po uzavření měsíce v DWH pro daný zdrojový systém. Data se nahrávají automaticky po jednotlivých zdrojových systémech samostatným procesem pro každý zdroj. Při nahrávání se stávající data nejprve vymažou a potom se nově vkládají.
Historie dat
Je udržována datová historie pouze pro jeden – aktuální měsíc. Data nejsou archivována.
Přístup uživatelů
Do této vrstvy mají přístup všichni uživatelé s právem pro výběr dat (select) bez možnosti data měnit. Tito uživatelé mají roli RRDM0_ALL_SELECT. Data zde lze upravovat pouze opětovným spuštěním standardního procesu nahrávání dat. (role RRDM0_ALL_CHANGE).
Umístění
Tabulky této vrstvy jsou umístěny pod uživatelem RRDM0_OWNER.
3.2 Vrstva L1
Popis
Vrstva L1 je plněna ETL procesem z vrstvy L0. Tato vrstva dále obsahuje výstupní tabulky z DaMiAs, která je dále využívána reportovacím systémem SDI. Součástí této vrstvy bude Data Correction Tool (DCT), což je pro Banku vyvinutý nástroj na opravu dat.
Tabulky jsou členěny stejně jako v L0, obsahují však navíc členění podle času – měsíční členění.
V této vrstvě budou také definovány tabulky OUT_GL_STAV_DETAIL a OUT_GL_STAV, do kterých bude systém DaMiAs vkládat data. Struktury těchto tabulek a indexy tabulky definuje Oddělení regulatorního výkaznictví. Tabulky budou mít členění podle času. Partition bude definována jako měsíční, vždy k ultimo měsíce.
Zpracování dat
Data jsou plněna na měsíční bázi. Kromě tabulek GL_ACCOUNTS, ACCOUNT FR BALANCE a GL_ACCOUNT_CLASSF_USAGES, které v L1 zcela chybí a tabulek ACCOUNT_GL_BALANCES a GL_BALANCES, které se v některých atributech odlišují, jsou tabulky shodné s vrstvou L0. Data v L1 mohou být upravována:
- Standardním spuštěním ETL procesu
- Manuálně prostřednictvím DCT
- Skriptem, který všechny změny ukládá do zvláštní log tabulky, společné s DCT
Historie dat
Požadavkem uživatelů je mít data dostupná po dobu 6 měsíců přímo v databázi a po dobu 10 let z offline zálohy. Obnova ze zálohy starší 6 měsíců by se prováděla jen na základě požadavku Oddělení regulatorního výkaznictví. Pro offline zálohu je navrženo rozšíření stávajícího Operátorského prostředí DWH o možnosti archivace databáze do formátu Oracle Export nebo Oracle Data Pump. Takto extrahované archivační soubory budou uloženy v archivačním systému Banky. Po dobu, než bude vyvinuta DWH Archivace, nebudou data v RRDM mazána. Předpokládá se nasazení DWH Archivace v průběhu jednoho roku, tj. data v L1 by měla být maximálně za 12 měsíců.
Přístup uživatelů
Do této vrstvy mají přístup všichni uživatelé s právem pro výběr dat (select) bez možnosti data měnit. Tito uživatelé mají roli RRDM1_ALL_SELECT. Data zde lze upravovat pouze opětovným spuštěním standardního procesu nahrávání dat. (role RRDM1_ALL_CHANGE) nebo skriptem resp. DCT s rolí RRDM1_DC_CHANGE
Umístění
Tabulky této vrstvy jsou umístěny pod uživatelem RRDM1_OWNER. Výstupní tabulky DaMiAs potom pod uživatelem OUT_OWNER.
3.3 Vrstva L2
Popis
Vrstva L2, jedná se o nezávislou část RRDM, bude spravována a řízena systémem DaMiAs. Do této vrstvy budou data nahrávaná z vrstvy L1 a dalších systémů, které budou ve správě administrátora DaMiAs. Pro tuto vrstvu bude vyčleněn tabulkový prostor 100 GB.
Zpracování dat
Data budou zpracovávána pouze prostřednictvím systému DaMiAs. Postupy a metody tohoto zpracování nejsou součástí tohoto dokumentu a ani nejsou součástí tohoto řešení.
Historie dat
Délka historie dat je řízena systémem DaMiAs.
Přístup uživatelů
Nepředpokládá se, že do této vrstvy budou přímo přistupovat uživatelé. Veškerá správa se bude provádět prostřednictvím DaMiAs, který bude využívat vlastníka této vrstvy DAMIAS_OWNER.
Umístění
Tabulky této vrstvy budou umístěny pod uživatelem DAMIAS_OWNER
4. Změny prováděné v DWH
Tato koncepce řešení RRDM nevyžaduje žádné zásadní změny v ODS/DWH kromě následujících:
- Budou doplněny procesy pro plnění a čištění tabulek RRDM do Operátorské konzole DWH
- Bude doplněna funkčnost Operátorského prostředí o DWH Archivaci
- Pro optimalizaci plnění - L0 mohou být v DWH vytvářeny dočasné – stage tabulky
- Externí číselníky klasifikací budou doplněny o nové typy
5. Požadavky na DaMiAs
Pro správnou práci s výstupními OUT tabulkami ve vrstvě L1 musí systém umožňovat tyto aktivity:
- Správu partition v OUT tabulkách (přidání nové, smazání obsahu – truncate)
- Správu indexů OUT tabulky (enable/disable/analyse)
Rušení partition bude prováděno v rámci procesu Purge strategie RRDM.
V případě požadavku na změnu struktury OUT tabulky, bude postupována standardním změnovým řízením.
V rámci akceptačních testů musí proběhnout integrační testy s DaMiAs.
Mezi RRDM a „starou“ DaMiAs databází bude vytvořen veřejný databázový link Pro využívání tohoto linku musí být na cílové straně vytvořen uživatel se stejným jménem a heslem jako na straně RRDM.
6. Shrnutí řešení
Celá koncepce hybridního data martu je navržena tak, aby byla snadno rozšiřitelná o další zdrojové systémy, což se i v dalších inkrementech předpokládá. Pro zpětné ověření dat bude, po dobu než dojde k převedení agendy všech zdrojových systému, která reporting vyžaduje, do RRDM zpřístupněno původní „starý“ DaMiAs data mart to prostřednictvím databázového linku.
Obecné výhody navrženého řešení jsou:
- Využití existujícího hardware, resp. jeho sdílení. Pokud bude nutné jeho posílení investice je provedena pouze na jednom místě
- Standardizovaná platforma (Oracle / UNIX)
- Je vyřešeno předání do provozu, zálohování a denní provoz
- Je zajištěna produkční podpora závislé části
Jiří Zamouřil (Oracle Consulting)
čtvrtek 7. ledna 2010
Alternativní Outer Join s použitím fiktivní faktové tabulky
Někdy je zapotřebí vidět v tabulce i hodnoty, pro které nejsou žádná fakta. Například požadavek zobrazit v určitém odbobí všechny země, ve kterých jsou prodejny a jejich prodeje, včetně zemí ve kterých se v daném období nic neprodalo.
Daný požadavek lze řešit pomocí Outer Joinu, který je dostupný v Business Modelu metadata repository. Ten je ale potom použit při každém dotazu a může mít vliv na rychlost dotazů vracených z databáze.
Alternativou je simulovat Outer Join s použitím „fiktivní“ faktové tabulky a nechat BI Server provést join mezi faktovou tabulkou a „fiktivní“ faktovou tabulkou provádějící kartézský součin.
Postup
Nejdříve vytoříme faktovou tabulku „DUAL“ jako select: SELECT 1 AS SHOW_ALL FROM DUAL a přidáme sloupec „SHOW_ALL“ do sloupců tabulky.

Potom nastavíme Complex Physical Join
 mezi tabulkami dimenzí, kde chceme simulovat Outer Join.
mezi tabulkami dimenzí, kde chceme simulovat Outer Join.


Vytřenou tabulku „DUAL“ přeneseme do Business Modelu a nastavíme Complex Joiny mezi tabulkami dimenzí.

Pro sloupec „SHOW_ALL“ je třeba nastavit agregační pravidlo, např. SUM a přidat sloupec do Presentation vrstvy, aby jej mohli uživatelé použít při tvorbě a definici reportů.

Ukázka reportu o prodeji podle prodejních kanálů a jednotlivých zemí. Bez použití hodnoty „SHOW_ALL“ vidíme pouze hodnoty za země a prodejní kanály kde byly nějaké obchody uskutečněny. Přidáním sloupce „SHOW_ALL“ dostaneme i přehled o tom, kde se prodeje neuskutečnili. Aby sloupec SHOW_ALL v reportu nepřekážel, tak jej:

Daný požadavek lze řešit pomocí Outer Joinu, který je dostupný v Business Modelu metadata repository. Ten je ale potom použit při každém dotazu a může mít vliv na rychlost dotazů vracených z databáze.
Alternativou je simulovat Outer Join s použitím „fiktivní“ faktové tabulky a nechat BI Server provést join mezi faktovou tabulkou a „fiktivní“ faktovou tabulkou provádějící kartézský součin.
Postup
Nejdříve vytoříme faktovou tabulku „DUAL“ jako select: SELECT 1 AS SHOW_ALL FROM DUAL a přidáme sloupec „SHOW_ALL“ do sloupců tabulky.

Potom nastavíme Complex Physical Join
 mezi tabulkami dimenzí, kde chceme simulovat Outer Join.
mezi tabulkami dimenzí, kde chceme simulovat Outer Join.

Vytřenou tabulku „DUAL“ přeneseme do Business Modelu a nastavíme Complex Joiny mezi tabulkami dimenzí.

Pro sloupec „SHOW_ALL“ je třeba nastavit agregační pravidlo, např. SUM a přidat sloupec do Presentation vrstvy, aby jej mohli uživatelé použít při tvorbě a definici reportů.

Ukázka reportu o prodeji podle prodejních kanálů a jednotlivých zemí. Bez použití hodnoty „SHOW_ALL“ vidíme pouze hodnoty za země a prodejní kanály kde byly nějaké obchody uskutečněny. Přidáním sloupce „SHOW_ALL“ dostaneme i přehled o tom, kde se prodeje neuskutečnili. Aby sloupec SHOW_ALL v reportu nepřekážel, tak jej:
- u kontingenční tabulky dáme do oblasti Vyloučeno
- u obyčejné tabulky nastavíme atribut skrýt ve formátu sloupce

Petr Podbraný (Oracle)
pondělí 4. ledna 2010

Seznam článků za Q4/2009 (říjen - prosinec 2009), seřazeno dle kategorie
BI Trendy
Compression
DWH
Essbase - FAQ
Exadata
Experts Bootcamp
GoldenGate
Novinky
OBI Apps - FAQ
OBI EE
OBI EE - DEMO
OBI EE - FAQ | OBI SE ONE - FAQ
OBI SE
ODI - FAQ
ODI / Sunopsis
OWB
Compression
DWH
- Metadata a navsteva u zubara
- Oracle University připravuje školení IMPLEMENT AND ADMINISTER DATA WAREHOUSE
- 4. Oracle Czech BI/DW Experts Bootcamp
- Oracle 11gR2 - Hybrid columnar compression
- Oracle Warehouse Builder 11gR2
Essbase - FAQ
- Instalace Hyperion Shared Services (HSS) na Oracle databázi s českou lokalizací
- Vytváranie Essbase kocky pomocou Essbase Studio 11g
Exadata
Experts Bootcamp
GoldenGate
Novinky
- Oracle University připravuje školení IMPLEMENT AND ADMINISTER DATA WAREHOUSE
- ODI a datový typ TIMESTAMP
- Oracle Day 2009
- Nové demo na BI Demo Serveru
- Oracle Warehouse Builder 11gR2
- OpenWorld 2009
- Oracle Discoverer a Reports ve verzi 11g
- Návštěvnost BI/DW Blogu za Q3/2009
OBI Apps - FAQ
OBI EE
OBI EE - DEMO
OBI EE - FAQ | OBI SE ONE - FAQ
- Hromadné změny v BI Answers reportech
- Vícenásobné řazení sloupců v tabulce na Dashboardu
- Instalace Oracle BI EE na Windows 7 pro testovací účely
- 4. Oracle Czech BI/DW Experts Bootcamp
- Dokumentační nepřesnost, týkající se „Security groups“ v metadatech BI Serveru
- Oracle BI – GO URL a české znaky
- Formátování čísel a NULL hodnot v kontingenční tabulce BI Answers
OBI SE
ODI - FAQ
- Oracle BI Apps 7.9.5.2 s ODI – mazání DWH po oblastech
- Úprava RKM pro automatické nastavení typu SCD sloupce dimenze
- 4. Oracle Czech BI/DW Experts Bootcamp
- ODI a datový typ TIMESTAMP
- ODI a OutOfMemoryError
ODI / Sunopsis
OWB
- Nové Oracle By Example pro OWB 11gR2
- 4. Oracle Czech BI/DW Experts Bootcamp
- Oracle Warehouse Builder 11gR2
Přihlásit se k odběru:
Příspěvky (Atom)