- Úvod do Oracle GoldenGate najdete zde.
- Popis integrace mezi Oracle GoldenGate a Oracle Data Integrator najdete zde.
- Popis instalace Oracle GoldenGate najde zde.
Začít replikovat data pomocí Oracle GoldenGate lze v následujících čtyřech krocích:
- I. Příprava OGG prostředí
- II. Konfigurace a start Extract (Capture) a Data Pump procesů
- III. Provedení inicializačního nahrání dat (synchronizace) ze zdroje do cíle
- IV. Konfigurace a start Replicat (Delivery) procesu
I. Příprava OGG prostředíNejprve je potřeba nastavit OGG prostředí: Manager proces, DB přístup a Supplemental logging jsou potřeba nastavit v homogenním i v heterogenním prostředí. Navíc v heterogenním prostředí se musí ještě vytvořit Source definition soubor.
1. Manager proces- zajišťuje administrativní úkony jako je startování, monitorování a restartování procesů
- musí běžet na zdrojové i cílové lokaci po celou dobu synchronizace dat (v mém případě zdroj i cíl je stejný, tj. jeden Manager proces)
- konfigurační soubor pro Manager proces se jmenuje ...dirprm/mgr.prm (když existuje a je prázdný, Manager proces použije default hodnoty, např. port 7809)
- logovací soubor je uložen v .../ggserr.log
- startuje se pomocí programu ggsci a příkazu START MGR nebo Windows Services (více viz. zde)
2. „Source definition“ souborV případě, že přenosy probíhají v heterogenním prostředí, pak je potřeba pomocí utility defgen vytvořit „source definition“ soubor, podle kterého Replicat proces provádí transformaci zdrojové struktury (např. datové typy) do cílové (v mém případě jde o homogenní prostředí, tj. soubor není třeba vytvářet).
3. DB přístup a Supplemental logging pro tabulkyOGG procesy potřebují přístup do databáze, potřená oprávnění viz. instalace OGG.
Pro testovaní mám v databázi uživatele OGG:
create user ogg identified by ogg
default tablespace users
temporary tablespace temp
quota unlimited on users;
grant dba to ogg;Dále pro správnou rekonstrukci UPDATE operací je potřeba do transakčních logů přidat dodatečné informace, tj. supplemental logging pro before & after image UPDATE operace. Minimální Supplemental logging byl přidán již v kroku instalace, zde.
Nyní se musí označit tabulky k replikaci pomocí OGG příkazu ADD TRANDATA. Pro Oracle 9.x a dále ADD TRANDATA zapne supplemental logging na úrovni databázových tabulek – příkaz vykoná ALTER TABLE ... ADD SUPPLEMENTAL LOG ...
Pro testovaní mám v databázi dva uživatele OGG_SRC a OGG_TRG:
create user ogg_src identified by ogg_src
default tablespace users
temporary tablespace temp
quota unlimited on users;
create user ogg_trg identified by ogg_trg
default tablespace users
temporary tablespace temp
quota unlimited on users;
grant connect to ogg_src, ogg_trg;Oba dva vlastní kopie tabulek uživatele SCOTT, ale pouze tabulky uživatele OGG_SCR obsahují data:
create table ogg_src.emp as select * from scott.emp;
create table ogg_src.dept as select * from scott.dept;
create table ogg_trg.emp as select * from scott.emp where 1=2;
create table ogg_trg.dept as select * from scott.dept where 1=2;Zapněte Supplemental logging pro db tabulky:
ggsci
dblogin userid ogg, password ogg
add trandata OGG_SRC.* 
Ověřte Supplemental logging pomocí:
info trandata OGG_SRC.* II. konfigurace a start Extract (Capture) a Data Pump procesů
II. konfigurace a start Extract (Capture) a Data Pump procesůExtract (Capture) proces zachytává transakce z redo logů a ukládá je do lokálního Trail souboru. Data Pump proces přenáší transakce z Trailu do cílové lokace.
A/ Extract procesProces bude zachytávat transakce z redologů a zapisovat je do lokálního trail souboru. Extract proces se konfiguruje na zdrojovém systému.
1. Vytvoření parametrického souboruKonfigurace procesů se provádí pomocí ASCII souboru, který bude uložen v adresáři .../dirprm/
ggsci
edit params EOGGSRC1
Vložte do souboru:
-- Parametr file pro Extract proces
-- zachytava zmeny nad tabulkama schematu OGG_SRC.*
--
EXTRACT EOGGSRC1
USERID ogg, password ogg
EXTTRAIL ./dirdat/ee
TABLE OGG_SRC.*;Uložte soubor
Poznámka: hesla ve všech konfiguračních souborech lze zašifrovat, jméno procesu je volitelné, exttrail určuje jméno lokálního trail file - dva znaky + OGG automatická sekvence (6 čísel)2. Přidání do Extract skupinyadd extract EOGGSRC1, tranlog, begin nowPoznámka: tranlog znamená, že data budou čtena z redo logůOvěřte pomocí:
info extract EOGGSRC13. Založení lokálního Trail souboruadd exttrail ./dirdat/ee, extract EOGGSRC1, megabytes 5 B/ Data Pump proces
B/ Data Pump procesProces bude přenášet data z lokálního trail souboru do cíle. Data Pump proces se konfiguruje na zdrojovém systému.
1. Vytvoření parametrického souboruKonfigurace procesů se provádí pomocí ASCII souboru, který bude uložen v adresáři .../dirprm/
ggsci
edit params PSRCTRG1Vložte do souboru:
-- Parametr file pro Pump proces
-- cte lokalni trail soubor pro tabulky OGG_SRC.* a prenasi do cile
--
EXTRACT PSRCTRG1
PASSTHRU
RMTHOST localhost, MGRPORT 7809
RMTTRAIL ./dirdat/rr
TABLE OGG_SRC.*;Uložte soubor
Poznámka: passthru se používá u Data Pump procesu když není požadována transformace nebo filtrování dat, RMTxxxx jsou parametry vzdáleného OGG2. Přidání do Data Pump skupinyadd extract PSRCTRG1, exttrailsource ./dirdat/eeOvěřte pomocí:
info extract PSRCTRG13. Založení vzdáleného Trail souboruadd rmttrail ./dirdat/rr, extract PSRCTRG1, megabytes 5 C/ Start Extract a Data Pump procesůstart extract EOGGSRC1
C/ Start Extract a Data Pump procesůstart extract EOGGSRC1
info extract EOGGSRC1
start extract PSRCTRG1
info extract PSRCTRG1 III. Provedení inicializačního nahrání dat ze zdroje do cíle
III. Provedení inicializačního nahrání dat ze zdroje do cíleInicializační nahrání dat ze zdroje do cíle zajistí prvotní synchronizaci obou systémů. Existuje několik metod jak prvotní inicializaci provést:
1. Prostředky GoldenGateGoldenGate umožňuje provést inicializační nahrání vlastními prostředky v heterogenním prostředí. Pro zajištění vysokého výkonu lze kontrolovat FETCHSIZE, paralelní zpracování a volní Bulk utility pro zápis do cíle. Proces zpracování může vypadat následovně:
Extract proces čte zdrojová data přímo z databázových tabulek (ne z transakčních logů) a posílá je do cíle:
- přímo na Replicat proces, který je zapisuje do cílových tabulek pomocí volání nativního SQL
- přímo na Replicat proces, který volá externí Bulk Loader (např. Oracle SQL*Loader API)
- přímo na Server Collector, který data ukládá do Trail file a Replicat je pomocí SQL zapisuje
- přímo na Server Collector, který data ukládá do souboru připraveného pro externí Bulk Loader
2. Prostředky databázíInicializační nahrání lze provést prostředky jednotlivých databází, jako je:
- Záloha zdrojové (primární) databáze a její obnova jako cílové (záložní)
- Export (exp, expdp) dat ze zdrojové databáze a import (imp, impdp) do cílové
- Přenos dat přes DB link
- Transportable tablespace
- ...
Níže je uveden příklad provedení inicializačního nahrání prostředky GoldenGate, kdy Extract proces čte zdrojová data přímo z databázových tabulek a posílá je do cíle na Replicat proces, který je zapisuje do cílových tabulek pomocí volání nativního SQL:
A/ Na zdrojovém systému1. Vytvoření parametrického souboru pro Initial Load Extractggsci
edit params EINILD1Vložte do souboru:
-- Parametr file pro Initial Load Extract
-- cte data z tabulek OGG_SRC.* a prenasi do cile na Replicat proces
--
extract EINILD1
userid ogg, password ogg
rmthost localhost, mgrport 7809
rmttask replicat, group RINILD1
table OGG_SRC.*;Uložte soubor
2. Přidání do Initial Extract skupinyadd extract EINILD1, sourceistablePoznámka: sourceistable znamená, že Extract proces čte data přímo z db tabulek a ne z redo logů
Ověřte pomocí:
info extract *, tasks B/ Na cílovém systému (v mém případě je stejný jako zdroj)1. Vytvoření parametrického souboru pro Initial Load Replicatggsci
B/ Na cílovém systému (v mém případě je stejný jako zdroj)1. Vytvoření parametrického souboru pro Initial Load Replicatggsci
edit params RINILD1Vložte do souboru:
-- Parametr file pro Initial Load Replicat (Delivery)
-- zapisuje data do tabulek OGG_TRG.*
--
replicat RINILD1
assumetargetdefs
userid ogg, password ogg
discardfile ./dirrpt/RINILD1.dsc, purge
MAP OGG_SRC.*, TARGET OGG_TRG.*;Uložte soubor
Poznámka: assumetargetdefs znamená, že struktura zdrojových tabulek je shodná se strukturou cílových tabulek, discardfile určuje soubor do kterého budou uloženy chybné záznamy, map mapuje zdrojové tabulky na cílové2. Přidání do Initial Replicat skupinyadd replicat RINILD1, specialrunPoznámka: specialrun znamená, že jde o jednorázové zpracování dat bez udržování ChekpointůOvěřte pomocí:
info replicat *, tasks C/ Start a kontrola Inicializačního nahrání dat
C/ Start a kontrola Inicializačního nahrání datStart provede dávkovou synchronizaci zdrojových tabulek uživatele OGG_SRC.* a cílových tabulek uživatele OGG_TRG.*
na zdrojovém systému:
start extract EINILD1
view report EINILD1
na cílovém systému (v mém případě shodný se zdrojem):
view report RINILD1 IV. Konfigurace a start Replicat (Delivery) procesu
IV. Konfigurace a start Replicat (Delivery) procesuReplicat proces čte cílový Trail soubor a aplikuje změny na cílové databázi. Replicat proces se konfiguruje na cílovém systému.
A/ Checkpoint tabulkaOracle GoldenGate pro případ obnovy přenosu po chybě systému využívá mechanismu Checkpointů. Checkpoints jsou použity pro uchování současné čtecí a zapisovací pozice jednotlivých GoldenGate procesů (Extract, Pump a Replicat) během přenosu transakcí. Checkpoints pro Extract a Pump jsou uloženy v Trailu.
1. Založení / úprava GLOBALS parametruggsci
edit params ./GLOBALSVložte do souboru
CHECKPOINTTABLE OGG_TRG.GGSCHKPTUložte soubor a ukončete ggsci pomocí příkazu exit
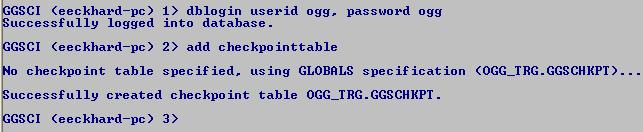
Poznámka: soubor GLOBALS (globální parametry systému) se musí jmenovat velkými písmeny, být bez přípony a musí být uložen v root adresáři OGG na cílovém serveru.2. Založení checkpoint tabulkyggsci
dblogin userid ogg, password ogg
add checkpointtable
 B/ Replicat proces1. Vytvoření parametrického souboruggsci edit params ROGGTRG1
B/ Replicat proces1. Vytvoření parametrického souboruggsci edit params ROGGTRG1Vložte do souboru:
-- Parametr file pro Replicat (Delivery) proces
-- zapisuje data do tabulek OGG_TRG.*
--
replicat ROGGTRG1
userid ogg, password ogg
assumetargetdefs
discardfile ./dirrpt/ROGGTRG1.dsc, purge
map OGG_SRC.*, target OGG_TRG.*;Uložte soubor
Poznámka: pro zabránění kolizi s inicializačním nahráním dat, lze použít parametr HANDLECOLLISIONS, který při INSERTu již existujícího záznamu (detekce duplicate-record) jej přepíše a při UPDATE nebo DELETE chybějícího záznamu (missing-record) zaznamená záznam do discardfile souboru.2. Přidání do Replicat skupinyadd replicat ROGGTRG1, exttrail ./dirdat/rr3. Spuštění Replicat procesustart replicat ROGGTRG1Ověření
info replicat ROGGTRG1Poznámka: pro zabránění kolizi s inicializačním nahráním dat, lze Replicat proces nastartovat od určitého SCN pomocí parametru ATSCN nebo AFTERSCN Testování replikace dat mezi zdrojem a cílem
Testování replikace dat mezi zdrojem a cílemV SQL nástroji spusťte DML operace nad tabulkou uživatele OGG_SRC, výsledek si následně ověřte nad tabulkou uživatele OGG_TRG.
1. InsertNa zdrojové db:...
...
insert into ogg_src.dept values (51,'APPS1','BRNO1');
insert into ogg_src.dept values (52,'APPS2','BRNO2');
insert into ogg_src.dept values (53,'APPS3','BRNO3');
insert into ogg_src.dept values (54,'APPS4','BRNO4');
insert into ogg_src.dept values (55,'APPS5','BRNO5');
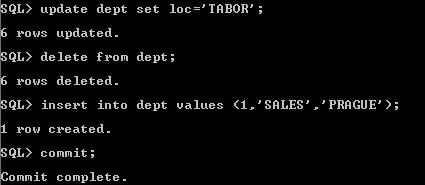
commit;Na cílové db:select * from ogg_trg.dept; 2. UpdateNa zdrojové db:update ogg_src.dept set LOC = 'TABOR';
2. UpdateNa zdrojové db:update ogg_src.dept set LOC = 'TABOR';
commit;Na cílové db:select * from ogg_trg.dept; 3. DeleteNa zdrojové db:delete from ogg_src.dept; commit;Na cílové db:select * from ogg_trg.dept;
3. DeleteNa zdrojové db:delete from ogg_src.dept; commit;Na cílové db:select * from ogg_trg.dept; OGG statistiky pro Extract a Replicat procesyNa zdrojovém systému (Extract proces):ggsci
OGG statistiky pro Extract a Replicat procesyNa zdrojovém systému (Extract proces):ggsci
send extract EOGGSRC1 report
view report EOGGSRC1 Na cílovém systému (Replicat proces):ggsci
Na cílovém systému (Replicat proces):ggsci
send replicat ROGGTRG1 report
view report ROGGTRG1 Zastavení OGG procesů (Extract, Data Pump a Replicat)ggsci
Zastavení OGG procesů (Extract, Data Pump a Replicat)ggsci
stop *
info * Zastavení OGG Manageraggsci
Zastavení OGG Manageraggsci
stop mgr
info mgr
Erik Eckhardt